Design and Implementation of a Personal Calendar with a Natural Language Interface in Turkish
(Turkish Speaking Assistant)
Sadi Evren SEKER
IMPORTANT
Some parts of report is removed, please contact for full version of report
You can copy, or modify any part of this report by the permission of authors only.
1. Introduction
NLP (Natural
Language Processing) aims to provide an effective communication interface
between human-beings and computer systems that has a very large scope based on
different application areas and languages. NLP programs convert natural language
sentences into a form that computers can handle by using morphological,
syntactic and semantic analyses, which are usually performed separately but
operate in coordination. We have implemented an interface for saving and
querying appointments via Turkish sentences using a utilized infrastructure.
The developed
program TuSA (Turkish Speaking Assistant) as the name implies fetches Turkish
sentences containing information the appointments and applies morphological,
syntactic and semantic analysis to convert them into logical formulas. This
program provides a way to query the desired appointment data set by parsing
these formulas. Although this program based on a utilizing infrastructure it
has its own.
To avoid an
ambiguity, at the beginning of the report we want to declare the terminology
about appointments. In any part of this thesis the term appointment means a
record in calendar database. Its subject can be a meeting, a dinner, an
interview or anything else. But the term meeting is always used to mean a
subject of appointment.
2. Literature Survey on Conversational Systems
First, we will
discuss some concepts and previous work related to our thesis. There are two
main issues in this thesis.
- Natural Language Programming and Machine Learning
- Calendar Programming and Calendar Database
2.1. Natural Language Programming &
Machine Learning:
One of the main
issues in TuSA is its natural language interface. Users can enter natural
sentences to teach the date, time, subject or location of their appointments.
The following sections cover previous studies on these fields.
2.1.1 The Turing Test
The Turing Test was
introduced by Alan M. Turing (1912-1954) as "the imitation game" in
his 1950 article, which he began by the following sentence [4]
I propose to consider the question "Can machines
think?" This should begin with definitions of the meaning of the terms
"machine" and "think."
Turing Test is meant to
determine if a computer program has intelligence. Quoting Turing, the original
imitation game can be described as follows:
It is played with three people, a man (A), a woman (B),
and an interrogator (C) who may be of either sex. The interrogator stays in a
room apart from the other two. The object of the game for the interrogator is
to determine which of the other two is the man and which is the woman. He knows
them by labels X and Y, and at the end of the game he says either "X is A
and Y is B" or "X is B and Y is A." The interrogator is allowed
to put questions to A and B.
When talking
about the Turing Test today what is generally understood is the following: The
interrogator is connected to one person and one machine via a terminal,
therefore can't see her counterparts. Her task is to find out which of the two
candidates is the machine, and which is the human only by asking them
questions. If the machine can "fool" the interrogator, it is
intelligent.
This test has
been subject to different kinds of criticism and has been at the heart of many
discussions in AI, philosophy and cognitive science for the past 50 years. [5]
2.1.2. ELIZA
ELIZA is a program operating which makes
certain kinds of natural language conversation between man and computer
possible. Input sentences are analyzed on the basis of decomposition rules
which are triggered by keywords appearing in the input text. Responses are
generated by reassembly rules associated with selected decomposition rules. The
fundamental technical problems with which ELIZA is concerned are:
1. the
identification of key words,
2. the
discovery of minimal context,
3. the
choice of appropriate transformations,
4. generation
of responses in the absence of key words, and
5. the
provision of an editing capability for ELIZA "scripts
When in conversation with ELIZA, the user
types in some statement or set of statements in natural language using normal
punctuation and sentence structures. ELIZA It then analyzes the user's
statement and generates some response which it types out.. Control is then
again with the user.[5]
A sample dialog
with ELIZA is shown below:
|
Men are all alike
IN WHAT WAY
They�re always bugging us about something or other
CAN YOU THINK OF A SPECIFIC EXAMPLE
Well, my boyfriend made me come here
YOUR BOY FRIEND MADE YOU COME HERE
H says I�m depressed much of the time
I AM SORRY TO HEAR YOU ARE DEPRESSED
It�s true. I am unhappy.
DO YOU THINK COMING HERE WILL HELP YOU NOT TO BE
UNHAPPY
I need some help, that much seems certain.
WHAT WOULD IT MEAN TO YOU IF YOU GOT SOME HELP
Perhaps I could learn to get along with my mother.
TELL ME MORE ABOUT YOUR FAMILY
My mother takes care of me
WHO ELSE IN YOUR FAMILY TAKES CARE OF YOU
My father
YOUR FATHER
You are like my father in some ways.
WHAT RESEMBLANCE DO YOU SEE
You are not very aggressive but I think you don�t
want me to notice that
WHAT MAKES YOU THINK I AM NOT VERY AGGRESSIVE
You don�t argue with me
WHY DO YOU THINK I DON�T ARGUE WITH YOU
You are afraid of me
DOES IT PLEASE YOU TO BELIEVE I AM AFRAID OF YOU
My father is afraid of everybody
WHAT ELSE COMES TO MIND WHE YOU THINK OF YOUR
FATHER
Bullies
DOES THAT HAVE
ANYTHING TO DO WITH THE FACT THAT YOUR BOYFRIEND MADE YOU COME HERE
|
Figure
2.1 A sample dialog from ELIZA
2.1.3. TOY
The TOY
conversation application and its corresponding natural language infrastructure,
developed as �etinoğlu�s M.S. thesis [2], form the basis of our system.
The lexicon and morphological, syntactical and semantic layers of TOY have been
used as the infrastructure of our program. Modifications and developments on
these layers have been done by following the approaches adopted in [2], such as
morpheme representation, DCG formalism and knowledge base querying.
Canan uyudu mu (Did Canan fall asleep?)
|
|
Bilmiyorum
(I don�t know)
|
Kemal uyudu mu? (Did Kemal fall asleep?)
|
|
Evet,
Kemal uyudu (Yes, Kemal fell asleep)
|
|
Canan
kucuk bir cocuktur. Kemal kucuk bir cocuktur. Butun kucuk cocuklar 10 saat
uyurlar. (Canan is a little child. Kemal is a little child. All little
children sleep for 10 hours.)
|
Kemal ne zaman uyudu? (When did Kemal fall asleep?)
|
|
Kemal
yirmi��te uyudu (Kemal fell asleep at 23 o�clock.)
|
Kemal ne zaman uyandi (When did Kemal wake up?)
|
|
Kemal
saat 9�da uyandi (Kemal woke up at 9 o�clock.)
|
|
|
Canan kahvaltida ne yiyecek? (What will Canan eat in the breakfast?)
|
|
Bilmiyorum
(I don�t know.)
|
|
Canan
kahvaltida peynir,ekmek,zeytin yiyecek (Canan will eat some cheese, bread,
olive in the breakfast.)
|
|
Tesekkurler
ogrendim (Thanks, I learned.)
|
|
Kucuk
cocuklar haric herkes kahvaltida cay icer (Everybody except little children
drink tea in the breakfast.)
|
|
Canan
kahvaltida ne icecek? (What will Canan drink in the breakfast? )
|
|
Bilmiyorum
(I don�t know.)
|
Canan kahvaltida cay icecek
mi? (Will Canan drink tea in the breakfast? )
|
|
Bilmiyorum
(I don�t know.)
|
|
|
Kac kisi kahvaltida cay icmeyecek? (How many people will not drink
tea in the breakfast?)
|
|
Bilmiyorum
(I don�t know.)
|
Kim kahvaltida cay icmeyecek? (Who will not drink tea in the
breakfast? )
|
|
Bilmiyorum
(I don�t know.)
|
Kac kisi kahvaltida peynir,ekmek,zeytin yiyecek? (How many people
will eat some cheese, bread, olive in the breakfast?)
|
|
Bir
kisi kahvaltida peynir,zeytin,ekmek yiyecek (One person will eat some cheese,
bread, olive in the breakfast.)
|
2.1.1.1 Kim kahvaltida peynir,ekmek,zeytin yiyecek? (Who will eat some
cheese, bread, olive in the breakfast?)
|
|
Canan
kahvaltida peynir,ekmek,zeytin yiyecek. (Canan will eat some cheese, bread,
olive in the breakfast)
|
Figure 2.2.� Target
scenario of TOY
The morphological,
structure of TOY have been adopted as a basis in our thesis.
2.2. Calendar Programming& Calendar
Databases
Under this
subject we will discuss another face of TuSA. As mentioned previously, TuSA is
an agenda to keep the appointments and answer when queried. The following
studies are about calendar programming. Unfortunately there is no calendar
program with a natural language programming interface.
2.2.1. Outlook-Calendar
Outlook is a
personal agenda, which can track the appointments [3]. Although it has many
functions such as contacts or mails, calendar module is strongly related to our
thesis studies. TuSA and Outlook have strong relations on their designs. By the
nature of an appointment fields of information are almost the same.
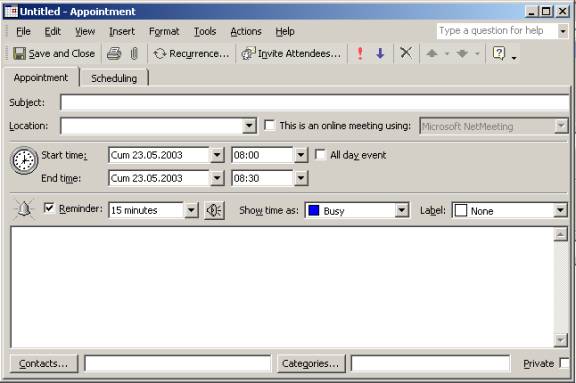
Figure
2.3 Outlook Appointment Insertion Interface
A simple
appointment in Outlook, keeps the following data (Figure 2.4.):
- Subject
- Location
- Contacts
- Date
- Start Time
- End Time
- Category
- Reminder
- Recurring (Figure 2.5.)
9.1. Recurrence Pattern
(Daily, Weekly, Monthly or Yearly)
9.2. Start of
Recurrence
9.3. End of Recurrence
Above
information is from the user interface of Outlook. There is no detailed
information about the database scheme or functionally dependent areas in
neither web site nor documentation of Outlook. For example given the start time
and the duration, you can compute the end time, and vice versa.
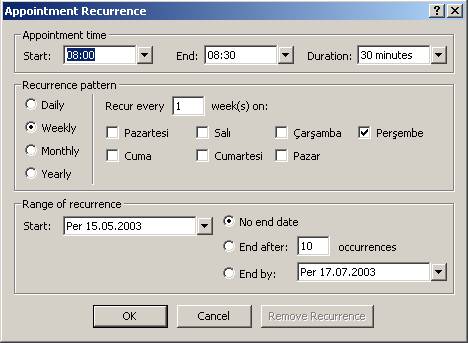
Figure
2.4. Outlook Recurring Appointment Insertion Interface
2.2.2. Korganizer:
In contrast to
Outlook, Korganizer is an open source project[7]. It is built on another open
source project, libical[8]. Again a GUI, very close to outlook is shown below:
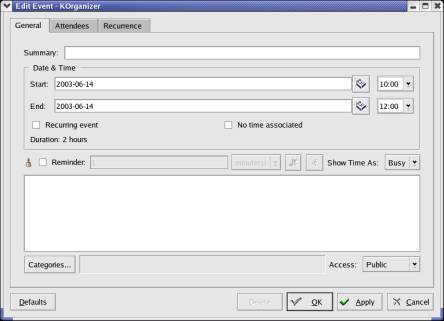
Figure
2.5 A sample GUI from Korganizer
And recurring
event window is show below, which is very close to outlook:
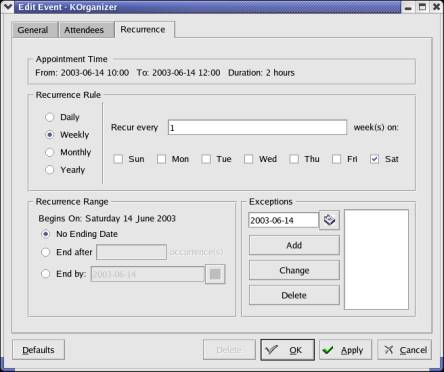
Figure
2.6. Korganizer Recurring Appointment Insertion Interface
Korganizer is another
agenda software which is coded for completely different environment.
Interesting thing between Korganizer and Outlook is their similarities. This
gives the idea that, most of the agenda softwares should carry similar information
fields, which we already covered during TuSA.
4. TuSA
4.1.����� Knowledge
Representation
For a NLP application, rather than trying to
analyze all possible Turkish sentences, which would be a very ambitious, in
fact an impossible task, we have limited ourselves to Turkish sentences that
deal with appointments. Since we want to implement a NLP application for a
sub-set of Turkish sentence structures, problems related to character sets,
lexicons and morphology are inherently problems for TuSA. Most of the work in
development phase of TuSA is done in syntax and semantic level, and a few modifications
are applied to the morphology used in TOY[2].
4.1.1 Syntax in TuSA
In the syntax level of TuSA, the most
important thing is the phrase concept. A phrase is a group of words. In the
most general form, a sentence is a phrase. But a sentence can be built of many
phrases, and each phrase can again be built of many phrases or words.
Sentence��������� → Phrase
Phrase������������ → Phrase | Word
|
Phrase Name
|
English
|
Explanation
|
|
Fiil
|
Verb
|
The command to TuSA
|
|
Konu
|
Subject
|
The subject of
appointment.
|
|
Kişi
|
Person
|
The person in the
appointment.
|
|
Yer
|
Location
|
The location of
appointment.
|
|
Zamanustu
|
Date
|
Time of appointment
in the names of days, months or years
|
|
Zamanalti
|
Time
|
Time of appointment
in the names of hour or minute
|
|
Uzunluk
|
Duration
|
How long is this
appointment?
|
|
Tekrar
|
Recurring
|
Recurring
information about appointment.
|
|
TS
|
Sentence
|
Biggest phrase that
can include all of the above.
|
Table
4.1. Syntactic Functions in TuSA
Phrases in TuSA correspond to the
possible data fields in any calendar program. Since each calendar program keeps
track of the subject of meeting, persons in meeting, location of meeting, date
and time of meeting, duration of meeting and recurring information, we have
built our phrase list as shown in Table 1.
Syntactic analysis starts with
the phrase Turkish Sentence (TS) which is the root for all phrase structure
rules. Starting from this phrase, many rules are applied in order to compute
the syntactic structure of any given input.
For instance, "Haftaya ona iki kala Aliyle Cananda
yedi saatlik toplanti var" (Next week at two to ten we have a seven-hour
meeting with Ali at Canan�s) is given to TuSA as an input.
This is matched to TS, and the
syntax analyzer tries to find possible phrases for each word and word groups.
Each word or word group is
assigned to a phrase at the end if the syntax of the sentence is correct as
shown below:
- Search all
phrases for word "Haftaya" (Next week) and match it to Zamanustu
(Date) phrase
- Continue
with the word "ona" (to ten), this yields no matches to a
phrase, so continue search with "ona iki" (two to ten) again
with no match, continue with "ona iki kala" (two to ten), and
find a match to Zamanalti phrase.
- Continue
with all words until the end of the sentence with that logical combination
process described above.
At the end TS yields a list of phrases as
below.
S->Zu Za P Y U K F
In the long form: sentence -> Zamanustu
Zamanalti Person Yer Uzunluk Konu Fiil
In semantic representation of Prolog -> takvim(3,15,58,9,1,2002,[ali],[canan],[toplanti],_,dur(7,hour)).
Zu = Haftaya (Next week)
Za = Ona iki kala (2 to 10)
P = Aliyle (Proper noun Ali)
Y = Cananda (at Canan)
U = Yedi saatlik (for 7 hours)
K = Toplanti (meeting)
F = Var (There is)
Since Turkish word order is free
and each phrase can go anywhere in the sentence, the phrases can be permuted.
All possible phrase combinations are listed in Appendix 1.
4.1.1.1. TuSA Syntax in Action
In TuSA, we have used
a special advantage of Prolog during our implementation. After converting the
input string into a list, all possible combinations of the syntax rules must be
tried to find the structure matching the input (if it exists) Fortunately
Prolog supports this kind of analysis with the built-in DCG (definite clause
grammar) feature.
For example we want to parse a sentence like
�Ali Beyle toplantı var�
(there is a meeting with Mr. Ali). Our character reader converts the input into
a list of words as, [ali,beyle,toplantı,var].
The next step is to find the correct phrases.
The first member is fetched from the list. It is attempted to be matched with
all the phrases one by one. Only one of them, the person phrase, provides a
successful match. So TuSA obtains the semantic representation of the word
�ali�, which is already �ali�.�
Next, the second member of the list is
attempted to be matched with all of the phrases. Unfortunately, �beyle� (with
Mr.) is inappropriate for individual match with any of the top-level phrase
types (because it is a �unvan� (title) phrase and these can only be sub
phrases of a person phrase). But TuSA is sometimes able to successfully
complete an analysis even if the sentence contains unknown words, as we will
discuss in person phrases. Unknown words are tolerated if they appear as
modifiers of other phrases.
So TuSA keeps the word �beyle� and continues
its search with �toplantı�.
This matches a konu (subject) phrase. So TuSA So TuSA tries to add the
previous word �beyle� (with mister) as a modifier to the subject phrase.
But TuSA has to make a final check to be sure that this is a possible
modifier(OK) The only way to be an modifier is being an unknown word. This
means if a word can not match any other phrases then we accept it as a
modifier. During this check, TuSA notices that the word �beyle� (mister)
is an �unvan�(title) phrase in fact. So TuSA can not accept this word as
a subject phrase.
At this point TuSA has to stop fetching
words, and backtracks to the word �ali�, which matched the person
phrase. The next step of TuSA is try to match the word �beyle� as a sub
phrase of the person phrase, if this were not successful, the sentence would be
rejected because of backtracking (DOGRU).Fortunately, the word �beyle�(mister)
is really meaningful in the person phrase.
So TuSA puts the word �beyle�(mister)
as a member of the person phrase and continues to fetch new words from input
list. Please notice that, the fetched word is �beyle�, but the word kept
in semantic representation is �bey� as shown in figure 4.1.
�The
next step of TuSA is fetching word �toplantı� (meeting) from the list. The most
appropriate phrase to this word is again the subject phrase. Since TuSA does
not need to backtrack and the current word has matched a phrase, TuSA continues
with the next word, �var� (exist). Again TuSA can find an appropriate
phrase in one pass, which is the verb phrase.
Syntactic parse of another example is given
in the chart below:
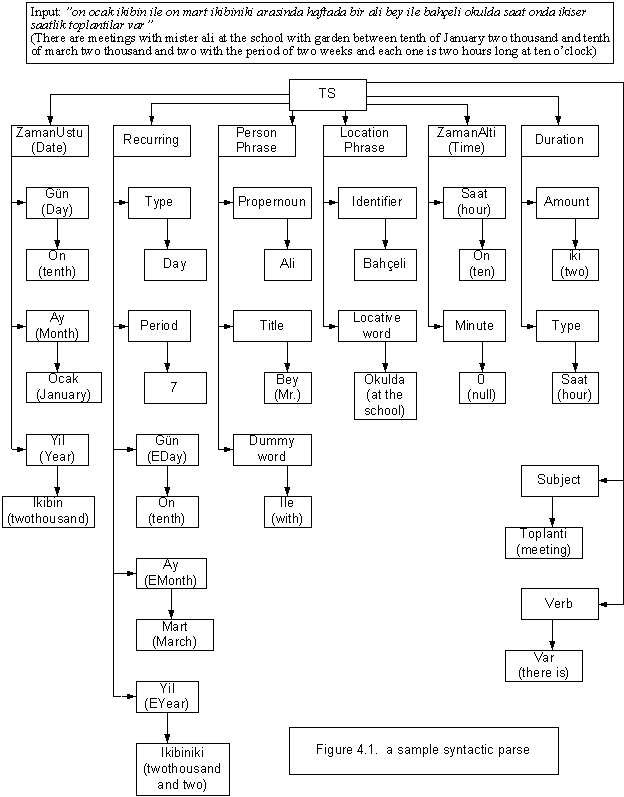
When TuSA has finished its search for
phrases, it can compute the semantic representation of these inputs. This point
will be discussed in the semantic section.
4.1.2. Proper noun(Person)
Phrases in TuSA
This phrase is used to catch the person
information about the appointment. Some of the appointment sentences can carry
the personal information, for example the sentence �Haftaya aliyle toplanti
var�(next week we have a meeting with Ali) carries the person information
of Ali which is a proper noun. So in any case, since we have a person
information in calendar programs, we do need to catch person information from the
natural language input and insert it into the calendar database.
A formal representation of person phrases in
this work� is as follows:
P-> Anything P
P-> P Unvan(title)
P-> Propernoun
So, a person phrase can only finish with
either a title or a proper noun and a person phrase can have many modifiers in
front of it. For example, �Ali Bey�(Mr. Ali) is an example to person
phrase where there is a title (�Bey�, Mr.) at the end of phrase �Ali �avuş�(Sergeant Ali) is another example to the person phrase, that
finishes with a title. On the other hand there may be any number of modifiers
in front of a proper noun to build a person phrase. For example, �Emekli General
Ali�(Retired General Ali) or a more challenging example may be �d�n gece
y�r�rken tanıştığım Beylerbeyi Lisesi M�diresi Canan
Hanım�(Mrs. Canan,
the Director of Beylerbeyi Lisesi, whom I met last night while walking).
We do not cover personal pronouns. In this
case most of the person phrases in Turkish end with a title or proper noun.
In the above formula, there is left
recursion, which should be avoided. There are other phrases but in this
recursion they can be accepted as Anything. For example, �okulda aliyle
toplanti var�(there is a meeting in the school with ali) is a good example
for the case. There is a word just before a proper noun, which is not a part of
proper noun. In fact it is a location phrase and it should be considered as it
is. But a person phrase can �eat� the location phrase, if the location phrase
is just before the person phrase. To avoid this, we have implemented a
mechanism to find the non-person phrases. A question should be raised at this
point as, how can we find the non-person phrases? The answer is obvious, all
other well-defined phrases are non-person phrases such as location phrases. So,
we have implemented a group of predicates which are holding non-person phrases.
And any non-person words are postponed for the search of other phrases by this
predicates.�
This has a negative side; in fact, we have
sacrificed all the proper noun possibilities containing other phrase words such
as location words in them. Since Turkish has extremely free syntactic rules,
all phrases can swim in the sentence, we have limited our work in simple
sentences. TuSA can not handle the nested sentences and users should not insert
such sentences as an input to TuSA. For example if we modify our previous
example as �d�n gece yemekte tanıştığım
Beylerbeyi Lisesi M�d�resi Canan Hanım�(Mrs. Canan, the Director of Beylerbeyi
Lisesi, who I have met last nigth at the dinner), we will have a problem to determine the
person phrase as it is and probably TuSA would understand �d�n gece
yemekte�(last night at the dinner) as the locative information of the appointment.
4.1.3. Location Phrases in
TuSA
This phrase is used to catch locative words.
In the sentence , �okuldaki toplantilari goster�(show the appointments in
the school), TuSA identifies school as the location of appointment. There
are two methods to identify a phrase is a location phrase or not.
- By using
the root of words
- By using
the suffixes
The first method seeks the locative word
roots, for example school is a location by its nature, and most probably it is
used to declare the location of the appointment. The second method seeks any
word which ends up with a locative suffix, for example �alide�(at ali)
phrase is a good example for this case. Its root is a proper noun and if the
suffixes are discarded, TuSA would consider it as a personal phrase, but under
the effect of locative suffixes it should be considered as a location phrase.
So any word that ends with a locative suffix (-dA), is considered as a location
phrase by TuSA.
Another problem, similar to the problem
discussed in the personal phrase section, is the descriptors in front of the
location phrases. The sentence �bah�eli okulda
toplantı var�(there
is a meeting at the school with garden) has this problem. Again we have implemented a similar solution to
personal phrases.
Y-> Anything Y
Y-> Anything(with locative suffix)
Y-> Location(a word, which is location by
its nature)
Again the �Anything� part yielded a left
recursion problem and we have solved the problem by filtering non location
phrases. For more information about suffixes please refer to the lexicons
chapter.
4.1.4. Subject Phrases in
TuSA
This phrase is used to catch information
about the �subject� of an appointment. If we discard the exceptions, all of the
appointment sentences includes a subject phrase. As previously discussed, the
subject phrase comes just before the verb phrase. So it is easy to define
subject phrase as the group of words which is just before the verb phrase. But
this has a big problem to differentiate the modifiers of verb and subject
phrase itself.� So we have solved the
problem by defining possible subject roots. The problem of possible modifiers
in front of subject is again solved by the formula below:
N-> Anything N
N-> Subject
Again we have implemented non subject phrases
to hinder the left recursion.
4.1.5. Duration Phrases in
TuSA
This phrase is used to catch information
about the duration of an appointment. Consider an appointment is one month long
and it repeats for every Monday, this information is not the duration of
appointment, we have covered it in section 4.1.8 recurring phrases, what we
mean by duration phrases is the duration of an individual appointment. For
example, a meeting for 2 hours long, has a duration information, which is two
hours. A recurring appointment may still have duration phrases. The sentence �
on ocak iki binden �onbeş
şubat iki bin ikiye kadar haftada bir iki saatlik toplantı var�(From January tenth of two thousand to
February fifteenth of two thousand and two we have meetings for each week and
they are 2 hours long), has both recurring information and duration
information.
This phrase is assigned to catch duration
words only. In TuSA, there is only one type of duration syntax.
����������� Duration���������� ->������ Number����������� Type of
Unit
Since we have two types of time units, the
Zamanustu (date) and the Zamanalti (time), we have to separate these unit
types. This differentiation is described in the semantics chapter, but in
syntax, it forces us to keep a type of time unit field.
4.1.6. Zamanustu (Date)
Phrases in TuSA
This phrase is used to represent information
about the date of an appointment. Although date is a time unit, it should not
be mixed with the time (zamanalti) of meeting. We have named this difference as
overtime and sub-time terms. Zamanustu (overtime, date) represents the meeting
date by the scope of week, month, day or year, on the other hand
Zamanalti(subtime,time) catches the meeting time by the scope of hour or
minutes.
Possible zamanustu(date) phrases are listed
below:
|
Formula
|
Sample
|
Translation
|
Form
|
|
Zu->Num Month Num(locative)
|
on ocak ikibinde
|
january tenth twothousand
|
Simple form
|
|
Zu->Num Month(locative)
|
on ocakta
|
january tenth
|
|
Zu->Num(locative)
|
Onunda
|
on the tenth
|
|
Zu->Timeunit(~locative)
|
Haftaya
|
next week
|
|
Zu->Month(locative)
|
Martta
|
in march
|
|
Zu->Num Timeunit Preposition
|
iki g�n
sonra
|
after two days
|
Relative form
|
Table 4.2. Zamanustu (Date) Phrases
This phrase is
essential for any agenda. Dates of meetings are fetched by using above
formulas. In Turkish, date format is somehow different than English, it is
ordered as day, month and year, while it is ordered as month, day, year in
English.
Another possibility is any number followed by
a month name, we have assumed that in such a case it is current year. For
example in table 4.2. �on ocakta �(ten january) is considered as current
year (2003).
Similarly if only a number is fetched, we
assume that this number belongs to the current year and current month. The
locative property is very important for this phrase, else there is a risk to
mix the input with Zamanalti(time) phrase, which� will be discussed in time phrase section
In Turkish, a locative time unit can also be
used to tell the date of an appointment. For example �Yarın�(tomorrow),
�Haftaya�(nextweek), �D�n�(yesterday) are some of the possible time units.
All the phrase forms discussed above are
simple forms, exact date is given in the phrase. But there is another type of
date insertion. Some of the users may choose to insert a date in relative form.
In the sentence �iki hafta sonra�(two weeks later), a relative date is
used. Each part of relative form is important, the number is used to understand
absolute value while the time unit is the multiplier of this number and the
preposition is used to understand the direction of this value. We can not say
the exact day of appointment by only using this phrase. We need to know the
current date to calculate the appointment date. TuSA has a date calculator
which calculates leap years, or day of week etc for such relative date
insertions.. (for further information, please refer to calendar functions in
TuSA section)
4.1.7. Zamanalti (Time)
Phrase
This phrase is used to catch the time of
appointments. As we have discussed in section 2.1.4, there are two different
time concepts for an appointment. The scope of this time phrase is the hour and
minute of the appointment, which is different than the date of the meeting or
the duration of the meeting.
Table 4.3 lists the all possible time
phrases:
|
Formula
|
Sample
|
Translation
|
Form
|
|
Za->Num Num(locative)
|
on ellide
|
at ten fifty
|
|
|
Za->Num Num(special) Preposition
|
ona �eyrek kala
onu beş ge�e
|
at quarter to ten
|
|
Za->Num Hour Preposition
|
iki saat sonra
|
after two hours
|
Relative Form
|
|
Za->Num Minute Preposition
|
elli dakika sonra
|
fifty minutes later
|
|
Za->Num(locative)
|
Onda
|
at ten
|
Table 4.3. Zamanalti (time) Phrases
Again we have two forms just like
Zamanustu(date) Phrase. The simple form holds all the time information in it.
On the other hand, the relative form needs the current time for calculating the
exact intended time slot.
There is another important ambiguity between
Zamanalti(time) and Zamanustu(date) phrases. For example, Za->Num is covered
by both phrases. The difference is in the suffixes, for detailed information
refer to section 4.2. morphology in TuSA
Another ambiguity is the Za->Num Timeunit
Preposition rule. Both phrases have the same rule, and we can not avoid the
acceptance of �iki hafta sonra�(two weeks later) as a time phrase in
this case. So we have solved this problem by clearly defining the time units in
time phrase. We did not implement a Za-> Num Timeunit Preposition phrase
under this phrase, instead we have implemented 2 different phrases which
already fulfills this requirement.
Za->Num Hour Preposition
Za->Num Minute Preposition
By merely defining the time unit members as
hour or minute here, we have avoided the ambiguity between time phrase and date
phrase.
Again for this phrase we have implemented the
calendar functions to calculate the relative time phrases. For example �onbin
saat sonra toplantı
var�(there is a meeting
after ten thousand hours) needs some calculations.
4.1.8. Recurring Phrases
This phrase is used to handle the recurring
events. As we have previously discussed in the chapter 2 literature survey, all
of the leading agenda programs have a recurring event option. Implementing such
a module for a natural language interface was one of the most difficult parts
of this study. One should always remember that there is a query mechanism,
separate from the insertion of the data. So translating the input to a semantic
formula is only a small part of the job. Most of the job for such a phrase is
done in the query part.
Table 4.4 lists the possible recurring event
entries
|
#
|
Formula
|
Example
|
Translation
|
|
|
|
her hafta
|
For every week
|
|
|
|
her ay
her yıl
her g�n
|
Every month
Every year
Every day
|
|
|
|
Haftada bir
|
For each week
|
|
|
|
Ayda bir
Yılda bir
G�nde bir
|
For each month
For each year
For each day
|
|
|
|
Her iki haftada bir
|
One a week
|
|
|
|
Her iki ayda bir
Her �� yılda bir
Her onbeş g�nde
bir
|
One in
two months
One in three years
One in the fifteen
days
|
|
|
|
Her Salı
|
|
|
|
|
Her iki haftada bir pazartesileri
|
every other Monday
|
|
|
|
Her ayın ikinci g�n�
|
Second day of each month
|
|
|
|
Her ayın ikisi
|
Every month second day
|
|
|
|
Her iki ayda bir ayın ���nc� g�n�nde
|
Third day of every two months
|
|
|
|
Her ayın birinci salısı
|
First Tuesday of each month
|
|
|
|
Her [yil] temmuzun ���nde
|
Every [year] third day of July
|
|
|
|
Her iki temmuzda
|
Every second day of July
|
|
|
|
Her temmuzun birinci pazartesisi
|
First Monday of every July.
|
|
|
|
Zamanustu
|
Date, as discussed in Zamanustu (Date)
phrases
|
Table 4.4. Recurring Phrases
There are -four types of recurring events
categorized by their periods,
- Daily
recurring events
- Weekly
recurring events
- Monthly
recurring events
- Yearly
recurring events
In table 4.4., formulas from 1-8 are daily
recurring events (some formulas have more than one time unit options, I assume
day is used in this case). They recur by the number of days. In fact every
weekly recursion can be converted to the daily recursions. For example �every
two weeks� means �every fourteen days�. Since week is a time unit, we needed to
separate it from other time units to make such a conversion.
Monthly recurring events are somewhat
different. They are listed in table 4.4. in rows 9-12 and rows 2, 4 and 6 are
also involved when month is used as a time unit. We need to separate daily
recurring events and monthly recurring events because, they are inadaptable to
each other.
For example we can combine weekly events with
daily events, because each week can be converted to 7 days in every condition.
But each month has a different day count. So we keep monthly recurring events
as they are, and parse their semantics when needed (for example in the case of
querying).
Yearly recurring events are again,
inadaptable to both monthly and daily recurring events. In table 4.4, formulas
13-15 are yearly recurring events, and rows 2, 4 and 6 are also involved when
year is used as a time unit. In formula 13, two different formulas are merged
and represented by an optional �[yıl]�(year), which is usually discarded
for simplification of phrase.
The last formula is for �kadar�(Until), which
is frequently used in recurring events. In fact there are 3 types of recurring
events by the beginning and end.
- Recurring
events with unknown beginning and unknown end
- Recurring
events with known beginning and unknown end
- Recurring
events with known beginning and known end
We can add a fourth type, the recurring events with unknown
beginning and known end, which exists only theoretically since there are no
practical samples in Turkish natural language for this case. First type is
infinite in both directions. We do not know when it starts and when it
finishes. So we have assumed that this kind of recurring event starts when the
record is inserted. For example if user enters the sentence �Haftada bir
toplantı var�
(we have a meeting every week), this sentence does not include any beginning or
finish information, we can not understand the starting date or final date of
the meeting series. But we can easily assume that this meeting has never been
done before the date it is entered. So we can easily convert the first type of
recurring events into the second type of recurring events. Similarly the fourth
type is mapped into third type.
For the second type of recurring events, we keep track of
recursion since it is cancelled. If the user enters a recurring event without a
deadline, it is considered as a live appointment and it is included in every
calculation or query.
Finally third type of recurring appointment carries the
beginning and final dates. How we keep the recurring events in our database
will be discussed in section 4.3. But in this case, important thing is the
insertion of final date. We have the Zamanustu (date) phrase for the beginning
date of the appointment, we have the recurring phrase for the recurring
information, but, how will we handle the final date? Answer of this question is
the last formula (16). It is obvious that every final date is a date and it can
be handled by our Zamanustu (date) phrase easily, the difference is in their
semantics, which will be discussed later.
4.1.9. Verb Phrases
This phrase is used to catch the action verb
at the end of the input sentence. We have used the name �verb phrase� but in
some cases the action word may be a non-verb word. In fact any predicate is
considered as a verb phrase by TuSA. There are 3 group of actions in TuSA
- Data Insertion
- Data Query
- Data
Deletion
And each action has its own verb sets. For
example, word, �var�(exist, there is), is considered as an insertion
verb; on the other hand, �g�ster�(show) is considered as a query verb.
4.1.10. Question Phrases
One of the most interesting
phrases is the question phrases. They are only used in the query sentences.
Words like �Ne, Nerede, Ka�, Kiminle, Kimlerle� (What, Where, How many, Whom with), are considered as the question
phrases. We create their semantics only temporarily to understand the command
and after the execution of command their semantics is not needed anymore. There
are only two types of question phrases declared in TuSA:
- Question
Phrase->Question word
- Question
Phrase->�ne� (How||What) + kadar(much)||zaman(time)
So in Turkish, Question phrases can be built
by a single question word or a question word supported by another meaningful
word. For example, �ne�(what) is a question word itself, but by
combining �zaman�(time) we can easily end up with �ne zaman�(what
time) which is still a question phrase with a different meaning. Another
example in TuSA is �ne kadar�(how much). So we have added a second rule
for question phrases to catch such word groups.
Question phrases was already coded in TOY
project but they were insufficient for TuSA to use them, because of the
semantic differences, so all of the question phrases has been coded again.
4.1.11. Syntax Summary
Syntax in TuSA can be viewed
by the following chart. Detailed listing of syntax is given in the Appendix 1
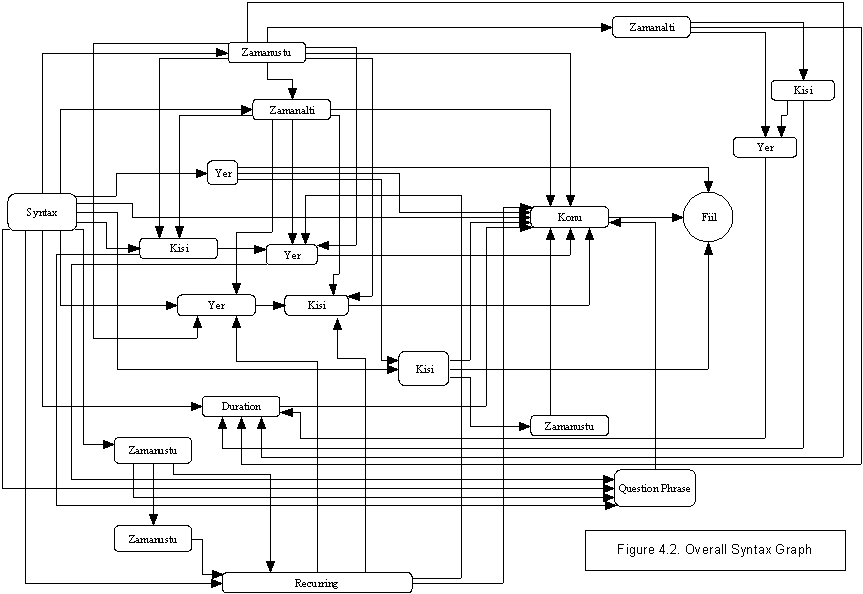
As shown in figure 4.2.,
each sentence in TuSA should start with a begining node called �Syntax�.
Finishing condition is only �Fiil� (verb) and rest of the phrases can be used
in many places. In fact each phrase can be used many times in Turkish
sentences, but we should force user to use a phrase only one time per input.
4.2. Morphology in TuSA
In Turkish, each word is constructed by
appending any inflectional and/or derivational suffixes to the roots in any
order by taking vowel harmony into account. Because of this nature, Turkish
morphology is really complicated for generating applications based on it.
Morphology of TuSA is essentially constructed
over the morphology of TOY project. In fact, there are only minor changes. The
biggest difference is the purpose of morphology between those two studies. In
the TOY project, both parsing and generation is designed, but in TuSA we use
morphology level to parse only.
Below you will find information about both
suffixes and roots. Our discussion will cover, FSM(finite state machine) of
suffixes, usage and comments about suffixes and we will continue to problems
about root. We will also cover some low level operations in morphology to make
everything clearer.
Then our discussion will continue with special
morphological issues, like morphology of numbers, time roots and question
words.
4.2.1. Suffixes in
TuSA
In TuSA finite state machines (one for nouns,
one for verbs and small FSMs for others) are used for parsing lexicons where
the initial nodes are possible roots and the final nodes are the ones reached
going through the arcs each of which represents a suffix addition.
There are two basic techniques in parsing a
word of an agglutinative language, namely, Root Matching (left to right) or
Suffix Stripping (right to left).
Root matching technique starts with searching
the prefix, tries to find a root and finishes with the search for postfix. In
each of three steps, there may be many possibilities to fulfill the
requirements, but finishing condition depends the combination of all steps.
Sometimes there may not be a possible way which yields an output, in the case
of incorrect inputs.
On the other hand, suffix stripping, which is
TuSA using inherently, does the job in reverse order. It starts by searching
for postfixes, finds an appropriate root and finishes with processing of
prefixes. Although there are a few prefixes and words which accepts prefixes in
Turkish, we have not implemented any prefix mechanism in TuSA.
In fact all the prefixes and the prefix
accepting roots in Turkish, come from other languages, such as Arabic or
Persian languages. [9,10,11]
This fact, forces us to accept only root or
root plus suffix input streams.
The word �stripping� comes from the parsing
algorithm in suffix stripping approach. When the parser finds a suitable suffix
in the input, this suffix is striped off from the input. Parser tries to strip
all the input by using available suffixes and roots in its database.
A widely used approach is the left to right
(root matching) approach. One reason for root matching approach, is that
parsing can be applied during insertion. Unlike suffix stripping approach, root
matching approach do not force user to insert whole input to start parsing.
Second and more important reason of widely usage is the efficiency. In root
matching approach, starting from root decreases the possibilities of suffixes
in the next step. For example, in the parse of the word:
(ali,
the proper noun)������������� (plural)�������� (preposition)��� =� (at the place of Ali)
geliyor
musun? (Are you coming?)
given to the FSM starting from possible verb
root, reaches one of the final nodes by producing the following deconstruction:
�����
gel� + Hyor�� +mH����������� + sun
(verb-root)(time)(question)(person2singular)
. H represents� �i� or �ı�and
is checked during the parsing operation to impose vowel harmony by taking the
previous vowels into account.
In the morphology level, TuSA searches the
most suitable words for the relevant phrases, as we have previously discussed
in the syntax chapter. Each phrase has its own morphological specifications. A
matching to a phrase can be done just by looking to the root of the word or the
final status reached by adding suffixes to the root, so search for roots and
search of suffixes are both implemented.
For instance, if the matching phrase is
Person, the program first searches the words with proper-noun roots. But this search is not enough to find correct
matching, another search is done on the suffixes of these words, and then the
correct words are found for the relevant phrases. For example, in the sentence
below:
�Aliyle
Cananda toplantı
var.�
(There is a meeting with Ali at Canan�s)
In this example both location and person
phrases have proper-noun roots. So correct phrase matching can�t be done only
by looking at the roots. As explained above, TuSA makes the correct matching by
looking at the suffixes of these words.
Any Turkish word can be matched to both
person and location phrases. The selection between these possibilities is
handled by the execution structure of Prolog. Because in Prolog each predicate
execution is done according the order they have programmed so if it satisfies
the first predicate than it does not continue to look for any other predicates.
So, the first possibility in the code is chosen and matching is done.
A similar example is between the
Zamanustu(Date) and the Zamanalti(Time) phrases. As we have discussed in syntax
chapter, both of these phrases can accept a single number word, such as �onda�(at
ten) or �onunda�(at tenth). Again the root of the words is number but
the difference is detected by looking their suffixes. �onda�(at ten) is
the Zamanustu(Date) phrase while �onunda�(at tenth) is the
Zamanalti(Time) phrase.
Another problem occurs in searching these
suffixes. As we have discussed in syntax level before, there are functions
working recursively and in any wrong ordered predicates case these recursive
functions cause left recursion, which is undesirable.
Since most of the words are constructed by
adding suffixes to the right of the root, for some special purposes in TuSA the
parsing operation on FSM are reversed and the words are parsed starting from
the final nodes in order to find the root. In some exceptional cases words are
given without any suffixes.
As we have mentioned before, TuSA is based on
the morphology of TOY[2], but we have made some minor modifications over this
infrastructure. Since TOY is designed for whole of Turkish sentences, its
morphology is concentrated on the big picture, which blinds it to some small
facts. Studying over a small set of Turkish has given us an advantage to see
the missing parts in morphology.
For example TOY is not strong in time phrases
like TuSA. In TuSA we have added a new root type the �ZamanK�k�(time root). Words like �Şimdi�(Now), �Yarın�(Tomorrow), �D�n�(Yesterday)
have special forms and they need to be considered as a different root type. For
example, there is a suffix (-ki) in Turkish and it is inappropriate with noun
roots. But for time roots it is meaningful and it is needed to add such a
suffix. So modified version of TOY FSM is in the following charts 4.3, 4.4 and
4.5.:
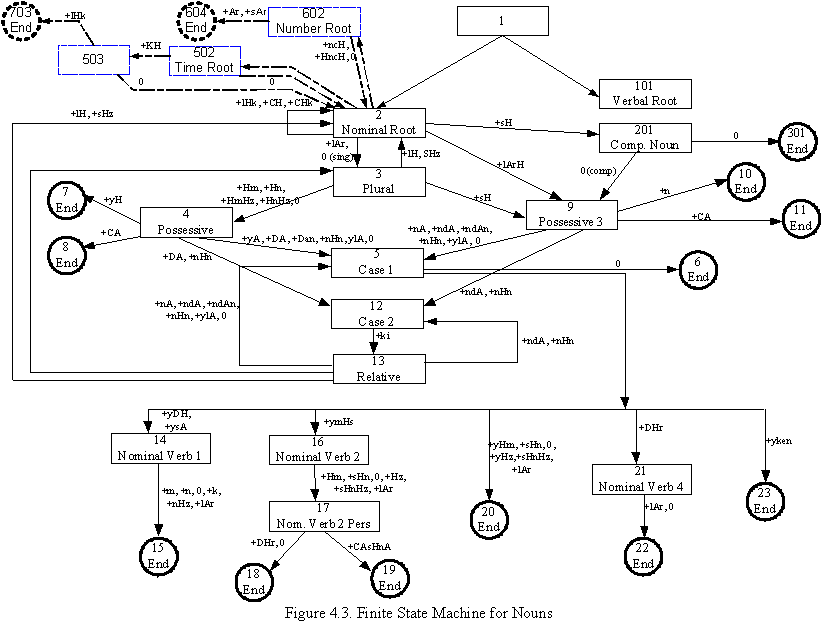
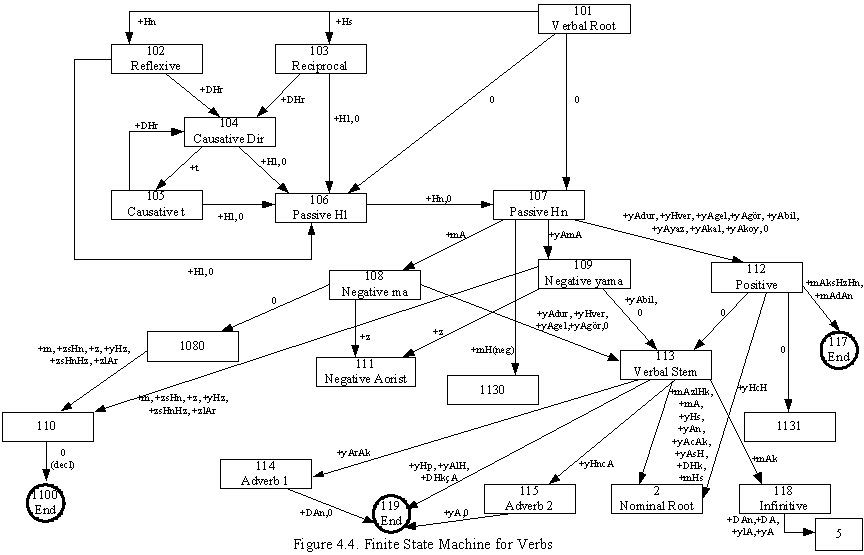
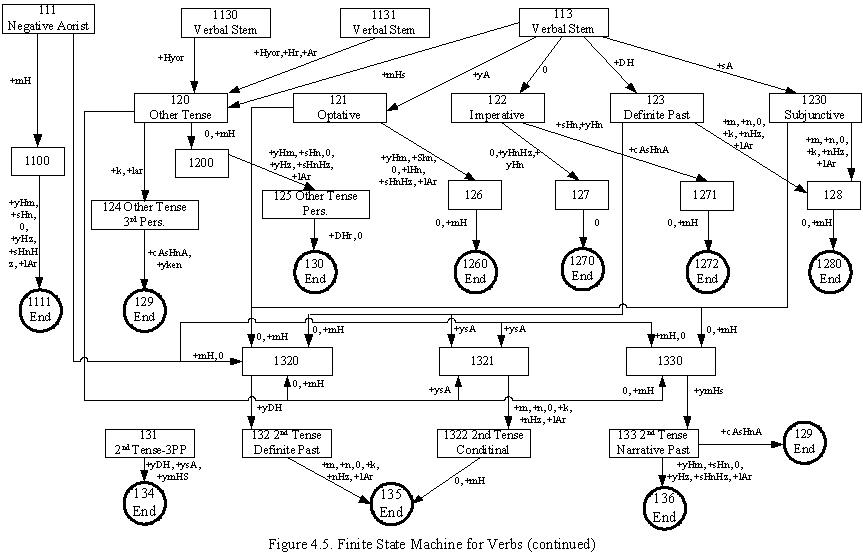
In the figure 4.3., the
dashed members are added during TuSA project. The rest is inherited from TOY-.
Although numbers and time roots are considered as nouns, they have some
differences from noun roots, this has forced us to create a FSM as shown above.
This FSM can work by
using the morphological functions. Since TuSA has changed the current semantic,
some of the morphological functions are rewritten.
Another problem about this FSM is, its parsing is always morphologically
correct but sometimes semantically implausible. For example, below examples may
give an idea about the problem:
Bak������� +�������� Hn�������� +�������� dH����������� +��������� m��������������������������������� Bakındım
(look)��������� (reflexive)����� (definite past)���� (peron
1 singular)������������� (I looked around)
Goster��� +�������� Hn�������� +�������� dH����������� +��������� m
(show)�������� (reflexive)����� (definite past)���� (person
1 singular)����� (I have showed by myself)
Former example
is both morphologically and semantically correct, while the latter is
morphologically correct but, semantically wrong. Unfotunatly above FSMs[Figure
4.3., 4.4., 4.5.] accept both input. To avoid such entrance, we need to make a
semantic check, which is almost impossible. Because, all roots and all affixed
roots, should declare the list of semantically possible suffixes. That is why
we do not accept incorrect inputs from user. Our input sentences must be
completly correct Turkish sentences to avoid such errors.
4.2.2. Roots in TuSA
There is a morphological
database inside TuSA which is inherited from TOY. In this database each record
is kept like a predicate. And each parameter of this predicate, identifies a
value of the coloumn. For example:
tr_morph_entry(�AdK�k�,[[�A�,l,i],[type(propernoun),sem(ali)]],_,_,_,i,i,ok).
Is an example record from this database. This
record keeps a noun root, which is proper noun and its name is Ali. The list
below shows the necessary information for each record in our root, morpheme
database:
- Label of
the morpheme
- Morpheme as
character list
- Meaning of
the morpheme or name of the suffix
- Last vowel
of the word that the morpheme affixed to (only for suffixes)
- Last letter
of the word that the� morpheme
affixed to (only for suffixes)
- State of
the word that the morpheme affixed to (only for suffixes)
- Last vowel
of the morpheme
- Last letter
of the morpheme
- State of the morpheme
Since its last letter is vowel, it is
declared in last second and third parameters by repeating same information �i�.
On the other hand, �sem(ali)� keeps the semantic representation of this word.
So in any case if the user enters a word starting with the root �ali�,
this morphological information will be used. Rest of the semantic will be
covered in semantic chapter.
Following table is the list of our word root
types (labels of the morpheme):
|
Type
|
Sample
|
Translation
|
Root
|
|
Verb
|
G�ster
|
Show
|
FiilK�k(verb)
|
|
Question
|
Kim
|
Who
|
SoruK�k(question)
|
|
Propernoun
|
Ali
|
|
AdK�k(noun)
|
|
Noun
|
Toplantı
|
Meeting
|
|
Ayadı(month)
|
Ocak
|
January
|
|
Unvan(title)
|
Bey
|
Mr.
|
|
TimePrep
|
�nce
|
Before
|
|
TimeUnit
|
Dakika
|
Minute
|
|
Number
|
Bir
|
One
|
SayıK�k(number)
|
|
Zamanustu(date)
|
Yarın
|
Tomorrow
|
|
Table4.5. � Morphological types & roots
In the TOY project
everything was either verb root or noun root, but by experience, we have needed
more specific types. For example in the char 4.2. (finite State machine for
noun roots) we have added time root, date, to catch suffixes, only specific to
this root type. On the other hand we have discovered, the meaning differences
by root. For example, both name of a month and name of a person are noun roots,
but they have different meanings in TuSA.
Each root type in the table has shown in the
chart 4.2., except the question root. We have created a root type called
question root because of the need for this type while parsing question phrases.
As it is discussed in question phrases, we only create the question semantic
temporarily, which forces us to create such a root type.
Separating roots into those categories has
also gained us more advantages. For example, we do not search Unvan (title)
root in Zaman (Time) phrases, while both is noun root.
Last vowel and last letter is used for vowel
harmony. Please remember the previous definition of suffixes. For example the
plural suffix in Turkish was declared as �-lAr� and we have declared that the
variable (capital letter) stands for both �a� and �e�. Morphological parser
accepts the appropriate form in this case. For example in the word
�(Ali, the proper noun)����������������� (plural suffix)
the plural suffix �-ler� substitudes �e� in
the variable of �lAr� to keep the vowel harmony. But as usual, all rules have
exceptions. For example the following word,
��������������� Kemal�������� +����������������� lAr�������������������� =������������ Kemaller
������������� �(Kemal)������������������� (plural
suffix)��������������������������� (Kemals)
is an exception.
Because the last vowel of the root is �a� and variable in plural suffix is �e�
which does not obey the vowel harmony. In such a case, we define the root as
follows:
tr_morph_entry(�AdK�k�,[[�K�,e,m,a,l],[type(propernoun),sem(kemal)],_,_,_,e,l,ok).
The last vowel of the word, �Kemal� is �a�
but we have declared it as �e�, which is the solution for the problem.
Another problem is
the letter changes, letter deletions or letter additions during affixations.
For example when the word below is entered to TuSA, it is successfully parsed.
But it can only be parsed by using an alternative suffix.
��������������� Ali�������������������������� +����������������������� yle����������������������� =��������������������� Aliyle
� �(ali, the propernoun)����������������������������� (relative suffix)����������������������������������� (with Ali)
Since the correct relative suffix is only
�le�, we have declared the following suffix for the above parsing operation.
Original suffix entry:
tr_morph_entry('ylA',[[l,A],[relative]],V,_,OK,A,A,ok)
:- vtoa(V,A), vok(OK).
Alternative suffix entry:
tr_morph_entry('ylA',[[y,l,A],[relative]],V,V,ok,A,A,ok)
:- vtoa(V,A), !.
For more detailed information about state
values of other arguments, please refer to TOY[2].
4.2.3. Morphology of
Numbers in TuSA
Again some parts of the work depends on TOY
project. As it is previously defined, all the roots should be entered in
morphology database. The biggest exception of this rule is the number phrases.
Our semantics level uses numbers in numeral
format, different than the accepted TuSA input. Since in a standard TuSA input
stream we accept only letters, numeral inputs are not accepted. But for
calculations and other calendar operations we need the numeral semantic of each
number inserted to TuSA.
In TuSA project we have added a new root type
Number Root, which is used to identify the numbers. In the previous TOY
definition, they have been accepted as a Noun Root, which hinders the special
suffixes for number roots. The only suffix we have added for number roots is
the counting suffix as shown below:
������������ iki�������� +���������������� şAr���������������������� =��������������������� ikişer
���������� �(two)���������������� (counting
suffix)��������������������������������� (two
each)
We have separated number roots from noun
roots, because counting suffixes are special to number roots only. We have
discovered such a missing part in recurring event entries, which will be
discussed in section 4.2.5 time root.
4.2.4. Time Root
Another addition to morphology of TOY done by
TuSA is the time root concept. Time phrases are used extensively in TuSA,
because of the nature of the application. Biggest reason to separate time root
from noun root is to determine time phrases much more easily. Another reason is
the special suffixes in time roots. For example during our studies we have
discovered that the only root type that can handle inflectional affixation of
the suffix �kH� is the time roots. Rest of the Turkish roots can handle the
affixation of suffix �kH� as a derivational suffix. For example:
yarın��������������������������������������� ki����������������������������������������������� yarınki
(tommorrow)���������������� (relative suffix)������������������������������� (tommorrow�s)
This suffix
makes no change on the semantics of the word, but still we need to define such
a suffix to handle this kind of insertions. Another example for the same
concept is the �lHk� suffix. For example by affixation of this suffix and a
time root we get the same semantic information, since it is a derivational
suffix for the rest of the noun phrases.
bug�n������������������������������������ l�k�������������������������������������������� bug�nl�k
(today)����������������������� (durational suffix)�������������������������������� (for today)
4.3.5 Question Words
One of the improvements over TOY is the
question words. We have not modified the yes/no question types, but we have
rewritten the question words in TOY. TuSA can accept any of the following
question words:
|
Question word
|
Translation
|
|
Kim
|
Who
|
|
Kimlerle
|
With who
|
|
Kiminle
|
With whom
|
|
Nerede
|
Where
|
|
Nerelerde
|
From what place
|
|
Ne zaman
|
When
|
Table
4.6. (question words accepted by TuSA)
4.3. Semantics in
TuSA
This is the most
important part of a natural language processing application like TuSA. For any
input, TuSA tries to find the related phrases by using morphology. And finding
phrase structure by syntax level, helps semantic level to gain meaning over the
sentence. Each phrase already converts inputs to a semantically representation,
but they are completely meaningless without a semantic level harmony.
As we have discussed
in the literature survey, all calendar programs create appointments with some
information. By default all appointments, have date, time, location, person and
subject fields.
So our approach in
the semantic level is similar to classical calendar programming with a NLP
extension. First we have built our semantic representation.
Prolog has a built in
relational database management system. This has gained us the power of keeping
each appointment in a database for further queries or deletion, insertion
operations. We have an external file �veriler.pl� to keep the database. It is
automatically loaded within the loading operations of TuSA. This keeps track of
every record permanently. Any insert operation to TuSA triggers an insert
operation on this file. Although there is an opportunity to keep the record in
the memory, we immediately dump the inserted information to the file, for
reliability reasons. A copy of this database is always kept in memory for fast
access. Query answering is done by the information in the memory.
The basic database
record structure in TuSA is as follows:
takvim(ID,Minute,Hour,Day,Month,Year,Person,Location,Subject,Duration,Recurring).
So by default each
appointment has the above fields, whether they are filled or not. For example
the input �Haftaya aliyle toplantı var�(There is a meeting with
ali, next week) has the following semantics.
takvim(234,0,8,27,5,2003,[ali],_,[toplantı],_,_).
In TuSA there are
three levels of semantic processing. First we gather some information from
input, than we try to create a knowledge base entry from this input and at last
we keep this knowledge in a database for further queries or updates.
1.
Fetched
information from input. Semantic representation of each word in this input is
created immediately. After a quick search in the morpheme database, TuSA can
create semantically representation of each morpheme.
2.
Some of the
information is not suitable for processing, for example date phrase �Haftaya�
(next week) is not suitable to write into the database. First of all it is a
relative date, so we need to convert this information to an absolute date. In
the second semantic level we do such conversions and try to find appropriate
form of information.
3.
Database form.
This is the third layer in our semantic implementation. Converting an
information to a processable knowledge is not enough for keeping and querying
this information. To do so, we create a unified and standardized form of
representation. And we collect the knowledge representation of each information
in this form.
In the following
sections, we will discuss the semantic of each field separately. We will start
from the ID field and continue our discussion till the Recurring field.
4.3.1 ID field
Since our information
about appointments is kept in a database, this field is the primary key of our
table. Each appointment has a unique identification.
�The next unused number for this purpose is
kept in a file called �id.pl� in the same directory with TuSA..
In query sentences,
we first try to build a set of identification numbers, and then we simply
display this set. For example if a user is looking for all the meetings in the
school, his input would be something like: �okuldaki toplantıları
g�ster�(show the meetings in the
school). After some sort of operations, a list of identification numbers will
return and our appointment displayer, which will be discussed in the interface
chapter, shows the appointments in this list.
4.3.2 Hour and
Minute fields
This field is
responsible from Zamanalti(time) operations. Most of the time phrases are in
number format. There are some exceptions for example the phrase �ikiye �eyrek kala� (quarter to two) has the word ��eyrek�
(quarter). This form of inputs should be converted to numerical
representations. There are such conversions in this part of semantic.
We have divided time
phrases:
�
Absolute time phrases
�
Relative time phrases
In absolute time phrases, we know the exact time. For example in the phrase
�ikide�(at two o�clock) we know that our appointment will occur at two o�clock
we do not need any further information. On the other hand, in the phrase �iki
saat sonra� (after two hours), our phrase tells us that, there is a meeting
after two hours from current time. So we need the current time to know the
exact time of appointment, plus we need a simple calculation. The former is an
absolute time phrase, while the latter is a relative time phrase.
In fact, time phrases are one of the most complicated phrases. As we have
already discussed, there are fields for time, in our semantic, the minute and
the hour fields. But in the case of relative time phrases, we can not place
semantic representation of input, since it is something contains a relative
part in its semantic. We have semantic transformation functions. They convert this
input into a meaningful format and then this form of information is inserted
into the semantic representation of TuSA.
These functions are:
|
Name
|
Sample
|
Translation
|
|
|
Parse time (parsezamanalti)
|
Onda
|
at ten o�clock
|
where, no minute information exists, so it is automatically considered as
0.
|
|
Parse time (parsezamanalti)
|
On
|
ellide
|
at ten fifty its semantics is 10 50
|
|
Parse relative time (parserelatifzamanalti)
|
on saat sonra
|
after ten hours
|
calculate, current time + 10
|
|
Parse relative time (parserelatifzamanalti)
|
��e beş kala
|
five to three
|
absolute time with relative representation, we need further calculation
for absolute time by the subtraction function
|
|
Parse relative time (parserelatifzamanalti)
|
onu �eyrek ge�e
|
quarter pass ten
|
absolute time with relative representation, we need further calculation
for absolute time by the addition function
|
Table
4.7. Zamanalti(time) phrase predicates
In TuSA, one of the
functions should be chosen for Zamanalti(time)phrases. We also have an hour
increaser function to calculate appropriate time of appointment. In fact this
function divides the number of hours into 24 and calls the dayincreaser
function, which will be discussed in Zamanustu(Date) semantic
If we encounter with
an input that does not contain any time phrase we automatically accept this
input as a day appointment. And we assign this appointment to eight o�clock in
the morning automatically, to avoid conflicts.
4.3.3. Date; day,
month, year fields
This fields of
semantic shows the date of the appointment. This semantic part can be executed
just after the Zamanustu(Date) syntax. Again we have two types of date phrases,
very similar to time phrases:
�
�
Absolute date
phrases
�
Relative date
phrases
In the absolute date
phrase, we know the date of appointment. For example, �on ocak ikibin�(january,
ten, twothousand) is an absolute appointment date. On the other hand, for
relative date phrases we need further calculations to insert an appointment.
For example the phrase �iki hafta sonra toplantı var� (there is a meeting in two weeks) is such an example.
It is possible to
encounter an input that does not contain any date phrase. In such a case we
assign the date information of the current date. For example in the above
example,
�saat ikide aliyle
okulda toplantı var������������ There is a meeting
with ali at two o�clock.
there is no date
information. And most probably the user has the current date in mind. So we
automatically assign the current date as the appointment date. In fact we do
not have any other choice.
Following functions
are the complete list of possible date phrase semantics.
|
Name
|
Sample
|
Translation
|
|
|
Parse date (parsezamanustu)
|
Onunda
|
on the tenth
|
There is no month or year information for the appointment, we only have
the day of appointment. So we automatically assign the current month and
current year to the appointment.
|
|
Parse date (parsezamanustu)
|
On ocakta
|
on the tenth of January
|
Again year field is missing, we assign the current year to the
appointment
|
|
Parse date (parsezamanustu)
|
On ocak ikibinde
|
on January ten twothousand
|
Absolute date
|
|
Parse date
(parsezamanustu)
|
haziranda
|
in June
|
Only name of month is given, we convert this meeting with beginning of
June 1 and duration of 1 month long.
|
|
Parse relative time (parserelatifzamanustui)
|
On gun sonra
|
ten days later
|
We make some calculations by our day increaser function.
|
Table
4.8. Zamanustu(date) phrase predicates
In TuSA, after the
syntax level, one of the above semantic functions should be chosen. In the
first step, syntax fetches the date information from user, it is not inserted
into the semantic representation, until the execution of above functions. Above
functions are responsible for inserting the date of appointment to the
semantic.
4.3.4. Overview of
date and time phrases
Since both date and time
phrases uses same set of words, such as the words with number roots. We have
made a differentiation between them. After syntax level, each type of semantic
representation has a unique view. For example semantic representation of
appointments with only day information have only one field of information while
the appointments with day and month information have two fields.
Since date and time
phrases do not written to the semantic formula directly in the syntax phase, we
have implemented a semantic processing function used only for date and time
phrases. This function is responsible to understand the type of information,
the missing part of information and also it is responsible for the appropriate
calculations.
4.3.5. Person,
Location and Subject
Semantic of these
fields are same, their semantic conversion is done in syntax level. Once they
are converted, the semantic representation of the input is inserted into the
appropriate field. For example �alilerde�(at ali) is a location phrase.
In the syntactic level, this word is converted to the semantic representation
of �ali� which is also �ali�. Since this input is a location
input, and the semantic representation is already found, it is automatically
written into this field in the semantic.
One exception may be
the modifiers of this kind of semantic fields. In the syntax level we have
covered that, there is a recursive loop to take all the possible modifiers as
they are. This modifiers are directly passed to the semantic level. This
information from syntax is merged with the semantic of the field, and it is
directly passed to the appropriate field in the semantic.
For example, �y�zbaşı
aliyle�(with captain ali) is
the inserted phrase. In the syntax chapter it is explained why this input is a
person phrase. �ali� is the final word and a proper noun. This tells us,
there may be an modifier in front of this word as in this example. We also
fetch the modifier, but we do not parse it like �aliyle�.
At the end, word �aliyle�
is parsed, and its semantic representation �ali� is found. On the other
hand word �y�zbaşı� is not parsed, since it is a modifier. And
we get the resulting semantic as �[y�zbaşı,ali]�. Since we do not need any calculations or
any further operation, we can directly copy this list to the appropriate field
in the semantic.
So in any field, in
person, location or subject fields, everything is same, only the syntax and
place of semantic differs.
4.3.6. Semantic of
Duration
Duration of an
appointment is not needed in each time but it is an essential part of an
agenda.
Again its semantic is
found in the syntax level, but there may be different types of durations like
time durations or date durations. In TuSA we rewrite date durations in the form
of time durations. For example a 2 day meeting is equal to a 48 hour meeting
for TuSA.
In fact, the most
common error is the mixture of recursion with duration. They are different
concepts. For example, a user may want to insert a sentence like �Bir haftalık
toplantı var� (There is
a meeting for a week). This sentence does not tell a week long meeting. S/he
wants to tell that every day this meeting will reoccur and length of this
recurring event is one week. So type of this meeting is recurring meeting. On
the other hand there may be duration information in sentences like, �I have
meetings next week, each ten hours long�. This is a more correct input because
a missing information in the previous example is completed in this input. In
fact, a human being can understand and fill the missing parts by his previous
knowledge. But a computer should only trust the input, so during this thesis
study we have never concentrated on filling such missing parts.
Because of above
limitations, there can not be a meeting a year or month long. So in TuSA there
are 2 types of durations:
�
Minute type
�
Hour type
We convert weekly or
daily long meetings to hour and keep this information in the duration field of
appointment. We have a second semantic representation for duration phrases.
Since prolog has a built in relational database implementation, we can consider
this second semantic representation as a second database table. In this table
we have two columns, the amount of duration and the type of duration.
By the light of above
explanations, we have the semantic representation below:
dur(30,minute)
There are some simple
conversions to calculate the correct amount of time and type. For example a day
long appointment should be converted to the type of hours by multiplying by 24.
Or another interesting example is the �yarım� (half) term,
massivly used. For example the input,
�aliyle yarım saatlik bir toplantı var� (there is a meeting with ali, half an hour
long)
has a hour term. And
as it is previously discussed in time phrases, half means 30 (like half past
two means thirty past two). Again we need to convert term �half� to thirty but
with an extra operation. We need to convert the type of duration from hour to
minute. Since half an hour is morphologically in terms of hour, it is
semantically in terms of minute.
4.3.7. Semantic of
Recursion
One of the most
complicated parts in TuSA is the semantic of recurring events. In relational
database terminology we can say that, this is the third table in TuSA. Since
each appointment can potentially have a recurring event information, we do keep
an empty field for every appointment. One of the second level semantic
representation is generated by this module. After insertion of a recurring
event, TuSA creates a new semantic representation for the recurring part of
this event. This representation is saved to the last column in global semantic
representation. If an appointment has recurring information, the semantic
representation below is used:
recur(Type,
Period, Period of month, Period of day number, Long format of day, Final day,
Final month, Final year)
As we have previously
discussed in the syntax chapter, there are 4 types of recursions. But in
semantic level we can decrease the number of recursions to three. Since weekly
recursions can be rewritten as daily recursions with 7 day periods, we have
decreased the number of recurring events to three in semantic level:
�
Daily recursion
(type in semantic is �day�)
�
Monthly
recursion (type in semantic is �month�)
�
Yearly
recursions (type in semantic is �year�)
We do not use eight
columns for each kind of recurring events. For example, daily recurring events
only use the first two columns. One of the most important reason to have eight
fields is the inconvertibility of recurring types.
Beyond this fact,
there are two sub types of monthly and yearly recurring events, and also they
can not be converted to each other too. Table 4.4.� in syntax chapter, holds all possible recurring types. In this
table all daily recurring types can be converted to each other and weekly
events can also be simplified to daily recurring events. But monthly and yearly
events should be separated. Table 4.9 summarizes each unconvertible form of
recurring events.
|
Type
|
Sample
|
Semantic Formula
|
|
Daily Recurring
Events
|
aliyle iki g�nde bir
toplantı var (there is a meeting with ali every two days)
|
recur(day, 2,
_,_,_,_,_,_)
|
|
Monthly
Recurring Events
|
|
|
|
Basic Monthly
recurring event format
|
her iki ayda bir ayın ���nc� g�n� toplantı var. (There is a meeting in the third day of
every two months)
|
recur(month, 2, _,
3, _,_,_,_)
|
|
Monthly recurring
events by the name of day.
|
her iki ayda bir ayın beşinci salısı toplantı
var. (There is a meeting on
the fifth tuesday of every two months)
|
recur(month, 2, _,
5, tuesday, _, _, _)
|
|
Yearly Recurring
Events
|
|
|
|
Basic Yearly
recurring event format
|
her iki yılda bir temmuzun beşinci g�n� toplantı var.
(there is a meeting on fifth
of july of every two years)
|
recur(year, 2, 7,
5, _, _, _, _)
|
|
Yearly recurring
event format by the name of day
|
her iki yılda bir temmuzun ���nc� perşembesi toplantı var.
(There is a meeting on third
Thursday of every july of every two years)
|
recur(year, 2, 7,
3, Thursday, _,_,_)
|
Table
4.9.Semantic representation of recurring events
Table 4.9shows that, there are three main categories
in the recurring events. And because of the long day format, we need to
separate both monthly and yearly events. Indeed we can not convert a long day
formatted recurring event into a number formatted recurring event. For example,
second Tuesday of march 2000 is 14th but second Tuesday of march
2001 is 13th day of the month. This forces us to keep the long day
format as it is.
4.3.8. Semantics of
Queries
Questions are the
basic units of querying commands. In fact there are two types of natural
language sentences that can query our calendar database.
1.
Question
sentences
2.
Sentences in
imperative format, with query verbs.
We have already
discussed the question sentences in syntax chapter. There are several question
words to query the database. Each can be used with different purposes. But
imperative query sentences are in the form of input sentences. The only
difference is the type of verb. By using this difference, we again build a
semantic representation of the sentence but this time we use to query the
database with this semantic representation. For example the two sentences below
have the same semantic representation.
Aliyle toplantı var.
(There is a meeting with ali)�������������� takvim(3,0,8,10,1,2002,[ali],_,_,_,_).
Aliyle toplantıları
g�ster. (Show the meetings with
ali)���� takvim(_,_,_,_,_,_,[ali],_,_,_,_).
Because only
difference is their verbs. We do not keep the verb in semantic representation,
it will be discussed in next section, semantics of verbs. But in imperative
form of queries, we can say that, they are only used to build a template for
query, and TuSA searches the records for this template. For searching
operations please refer to the section 4.4. calendar functions.
4.3.9. Semantics of
Verbs
In fact we do not
have any field in our semantic representation for verbs. Semantic of verbs are
temporarily created and after the execution of verb, it is completely
destroyed. We have three type of verbs:
�
Query verbs
�
Insertion verbs
�
Deletion verbs
The most used verb
types are query verbs and insertion verb. Most of the time, when a user wants to
insert a new entry into the calendar database, some of the missing parts are
automatically filled in by TuSA. For example an entry without the date
information probably means a meeting today. So filling in the missing parts in
insertion verbs is important may be risky, but on the other hand, for query
verbs, it would be a big mistake to fill the missing parts. For example if a
user wants to query a meeting with Ali, most probably user does not enter any
date information. And if TuSA automatically fills in this area, the user can
only see the meetings with Ali in today, which is an unwanted situation.
Deletion verbs are
used to cancel an appointment. There is a delete function working on calendar
functions level, and any sentence with such a verb triggers this deletion
function. Please refer to the calendar functions for further information.
Semantic
representation of verbs are generated as level 1 semantic representation in the
syntactic parse phase. After this generation the semantic representation of the
appointment is carried to the execution functions of TuSA. Each verb family
refers to a different execution function. Below figure shows the flow diagram
of execution steps in TuSA.
4.4. Calendar
Functions
During the execution
of TuSA, we frequently need some calendar functions. For example in order to
show the day of week, we need some calculations. Those calendar calculations
are explained in this chapter.
Some problems like
leap years are taken into account in the below functions. During their
explanations, such low level problems will not be explained.
4.4.1 Day of week
and Date matching functions
In the example input
below, date of appointment is given in long day format. In order to insert an
absolute value into the calendar database, we need to convert this long date
format to the form of day, month and year. This operation is handled by day of
week function.
�Pazar aliyle
cananda toplantı var� (there is a meeting with ali at canan, sunday)
Another important job of DOW
function is in the query sentences. When a query sentence like below is entered
in TuSA prompt, the answer should contain a long day format. Please refer to
execution of TuSA chapter for more information.
Last and most
important usage of DOW function is in the recurring events. As it is previously
discussed in recurring events section, some monthly and yearly recurring events
can keep day in long format. In such a case, querying functions should check
for the long format of the day.
Date matching
function uses DOW function to see if those two dates are equal for long day
format. On the other hand, date matching function can return the relation of
two given dates like first is later, or first is earlier than the second one.
This kind of matching is needed while querying a date slice or recurring
events. For example, to query a recurring event with a final date, we need to
query each occurrence of the recurring event by date increasing function. But
we should stop our search just after reaching the final date or the date we are
seeking, else we would search infinite probabilities.
4.4.2. Day increaser
& Time increaser functions
For many reasons we
need these functions. Time increaser increases the given hour, day, month and
year. Each of these fields are critical. For example, if a relative time phrase
like �oniki saat sonra toplantı var� (there is a meeting in 12
hours)is inserted just before the new year, TuSA should calculate the absolute
date of this appointment for next year. In any case if the date information is
missing for an entry, TuSA automatically fills these missing variables, to make
system more robust, as previously discussed in date phrases.
Day increaser on the
other hand is useful for recurring events to check each occurrence of the
event, or to convert any relative date phrase to an absolute date phrase.
4.4.3. Search
Functions
In any case of querying an information, e.g. querying a person, TuSA needs
to call these functions. Since each information is categorized under the
semantic representation, TuSA only searches the appropriate fields. For example
searching the meetings with Ali is only done for person field in our semantic
representation.
Result set of these searching functions are the id numbers of the records.
On the current system, these search functions are used under the query and
deletion sentences, so these id numbers in the result set are either printed to
the screen by formating the appointment informations or deleted immediatly. But
these functions are ready for further usage such ase moving an appointment to
another date.
A user can search the following fields in TuSA:
4.4.4. Question
Functions
Different than
search functions we have implemented question sentences. Search functions are
used to answer the imperative query sentences, but for the query sentences with
question words, we have implemented different functions. Because most of the
time imperative query sentences, queries the entire appointment, or deletes the
entire appointment. But question phrases are used to collect some information.
For example the question word �Kim� (who) is used to find a set of
person. Here the term �set� is important, because if a user queries our
database and asks the person names of next weeks appointments, than our answer
should contain one member from each name. If user has three meeting with �ali�
for example, we should show �ali� only one times, which is inappropriate
for imperative query sentences.
On the other
hand sometimes question phrases do not query an information from the
appointments. For example �Ka��
(how many) is such a question phrase. The queried information for this kind of
question phrases can be answered by some special functions executed over the
appointments.
4.5. Execution of
TuSA
4.5.1. Data
insertion to TuSA
User inserts the sentence ��Haftaya ona iki kala arkadasim Aliyle komsumuz Cananda yedi
saatlik yemekli bir toplanti var� (Next week, at two to ten, we have a
diner with my friend Ali at our neighbor Canan for seven hours)� using�
the XPCE input screen offered by TuSA
The sentence is sent to Syntax analyzer
(starting from TS predicate explained in Section 2) for matching each word or
word group to phrases. During this matching process TS tries lots of predicates
in the program and except one of them ends with failures like a matching try of
�Haftaya� (next week) to person,
location,�All these tries ends with a matching like the Date phrase in the
example. In most of the cases, more than one predicate (Zu)has to be checked in
order to match or mismatch the word to that phrase. In this example, although �Haftaya� is a word that can be accepted
by one of the Zu predicates, it doesn�t match the first of them Zu� GAY. In
order to come over these drawbacks TuSA checks the same word in all 8 different
Zu predicates. After these checks, it concludes whether it matches the date
phrase or not.
Syntax analyzer stops execution when all
words are matched to phrases.
After syntax analyzer returns the results in
the form shown in Table 4, semantic representation of the sentence is
constructed. The below example shows how a word group is translated into
semantic representation.
��komsumuz
Cananda� (at our neighbor Canan) is the input for TS in this case.
TS searches until reaching person phrase
without any match and� tries to satisfy
person phrase. In this case Canan is naturally a person phrase because it is a
proper-noun. TS searches for three different sub-functions and finds the Person
� Anything
Propernoun at the end. TS ignore Anything part (in this case �komsumuz� (our neighbor) is ignored).
But there is one more check to satisfy this condition. TS checks for its
suffixes. (In this case Canan (proper noun root) + -da (Locative suffix)). It
does not accept this word group as a person phrase because there is no suitable
person phrase definition. Only definitions on proper noun in person phrase are
Person � Propernoun(without any suffixes) Person �
Propernoun(with relative)
So TS continues to search for other phrases
and finds the location phrase. In this case TS satisfies the location phrase
because it accepts the Location -> Anything Propernoun (locative)
So the semantic of
input word �komşumuz Cananda� (our neighbor Canan) is returned to
TS. In this case semantic of this word is [komsumuz ,Canan]
and TS yields out the following semantic
representation:
takvim(11,9,58,22,11,2002,[komsumuz,canan],[arkadasim,ali],[yemekli,bir,gorusme],7,'saat').
where,
takvim(id of this record, minute,
hour, day , month , year , location, person, subject, duration, duration unit).
Some comments on semantic:
Id is an automatically incremented value to
keep each meeting unique. All minute, hour, day, month and year is calculated
by simple arithmetic operations. For instance, if the input is relative time
(e.g. �ikibin saat sonra� (after two thousand hours)), TuSA gets current
time from operating system, converts 2000 hours to year, month, day and adds
this value to current time, and makes arrangements for increment operation
(some times day value is bigger than 30 for example so it get mod. 30 for day
and adds division to month etc.)).
|
Input in Turkish
|
English
|
Phrase
|
Phrase name
|
|
Haftaya
|
Next week
|
Zu
|
Date
|
|
ona iki kala
|
at two to ten
|
Za
|
Time
|
|
|
with my friend Ali
|
P
|
Person
|
|
komşumuz Cananda
|
at our neighbor Canan
|
Y
|
Location
|
|
yedi saatlik
|
for seven hours
|
D
|
Duration
|
|
yemekli bir toplantı
|
a diner
|
K
|
Subject
|
|
var
|
there is
|
F
|
Verb
|
Table
4.10 Parsing Phrases during execution
Location, person and subject fields are
lists. As discussed before, it is possible to enter several words to these
areas. So we keep them as list to hold this kind of input. Duration is kept as
an integer value and duration unit keeps the unit of this duration (minute, hour,
day, month or year) If it is a very high number (greater than 100), it is
automatically converted to a higher unit.
This semantic output is saved on a file. This
file can be used as a relational database itself, because of the nature of
Prolog.
4.5.2. Querying in
TuSA
TuSA can be used not only for inserting the
appointments but also querying. Again the same graphical user interface is used
for getting the user�s query sentences. For instance, if the following sentence
is given,
�Haftaya Aliyle olan yemekli
toplantıları g�ster�
(Show the dinners with Ali)
The program first converts the sentence to
semantic representation explained in section 2.4.1 and yields out the following
semantic
takvim(_,_,_,22,11,2002,_,[ali],[yemekli,toplanti],_,_).
This semantic representation is used as a
template and the program tries to find word or word groups for each empty
phrase location over the database file. In this process the elimination of the
records is done by using the phrases in the semantic representation.
If any result is found, they are shown in the
following format to the user:
---------------------------------------------------------
ID:11
Tarih:22/Kasim/2002|09:58|Cuma
(Date:22/Novenber/2002|09:58|Friday)
Kisi:
arkadasim ali (Person:� my friend ali)
Yer:komsumuz
Canan
(Location: Neighbor Canan)
Konu:yemekli
bir toplanti (Subject:
Dinner)
Suresi:7
saat (Duration: 7 hours)
Semantic:
takvim(11,9,58,22,11,2002,[komsumuz,canan],
[arkadasim,ali],[yemekli,bir,gorusme],7,'saat').
---------------------------------------------------------
5. Environment
Specifications
�Programming Language: Prolog is used as the programming language,
which consist of first order predicate calculus and it can be used as a
relational database by� its nature.
�Developing Environment: SWI-Prolog which is developed at University
of Amsterdam is used as the programming environment. XPCE is used as the
graphical user interface module.
�Operating System: Swi-Prolog is an open source programming
environment so it can run almost every operating system, but TuSA is tested
under only Windows 98/2000 and Linux. I should inform you about the Turkish
character set problems under Linux.
6. Conclusion
TuSA, Turkish
Speaking Assistant is an initiative in its area which is implemented for
storing appointment information using Turkish natural sentences and can
cooperate with the applications based on the same infrastructure developed by
�etinoğlu[2]. TuSA is an ongoing application and new additions will be
done until a web interface, MS Outlook synchronization and phonetic usage are
added to it. The chosen language, environment and the extendibility of the code
will ease the desired additions.
The general
information and usage examples and milestones can be accessed via TuSA
homepage(http://www.shedai.net/tusa) on the internet.
[1] Covington,
Micheal A., Natural Language Processing for Prolog Programmers, Chapter 1,
Prentice-Hall Inc, New Jersey, 1994
[2] �etinoğlu �zlem, A Prolog Based Natural Language
Processing Infrastructure for Turkish, M.S. Thesis, Boğazi�i University,
2001
[3] Microsoft Outlook,
http://office.microsoft.com
[4] Computing
Machinery and Intelligence (Mind, Vol. 59, No. 236, pp. 433-460)
[5] ELIZA � a
computer program for the study of natural language communication between man
and machine , Joseph Weizenbaum Massachusetts
Institute of Technology, Cambridge ,ACM Press New York, NY, USA, Pages: 23 � 28, Periodical-Issue-Article,
Year of Publication:1983, ISSN:0001-0782
[7] KOrganizer,
KDE, korganizer.kde.org/dox/korganizer/hierarchy.html
[8]libical,
Software Studio, www.softwarestudio.org/libical/UsingLibical/
T�rk Dilbilgisi. Dil - Sesbilgisi - Bi�imbilgisi - C�mlebilgisi.(Turkish
grammer, phonetics, morphology, syntax)
[9] �lk�, Vural:
Affixale Wortbildung im Deutschen und T�rkischen. Ein Beitrag zur deutsch-t�rkischen
kontrastiven (Grammatik Morphology in German and Turkish roots). DTCF Press No:
294. Ankara. 1980
[10] Ediskun,
Haydar: Remzi Kitabevi. İstanbul. 1985
[11] Gencan,
Tahir Nejat: Dilbilgisi. G�zden Ge�irilmiş IV. Baskı. (Grammer, 4th
edition) T�rk Dil Kurumu Press: 418. Ankara. 1979.
[12] Oflazer, Kemal: Turkish
Natural Language Processing Initiative : An Overview, TAINN, 1994
APPENDIX 1 � Syntax
Groups
Simple Syntax Group:
|
Formula
|
Sample Sentence
|
Semantic
|
|
S->Konu Fiil
|
toplantı var
|
takvimsem(_, 0, 8, 7, 5, 2003,
_, _, [toplanti], _, _)
|
|
S->Kisi Fiil
|
alileri goster
|
takvimsem(_, _, _, _, _, _,
[ali], _,_, _, _)
|
|
S->Yer Fiil
|
okuldakileri goster
|
takvimsem(_, _, _, _, _, _, _,
[okul], _, _, _)
|
|
S->Yer Kisi Fiil
|
okuldaki alileri bul
|
takvimsem(_, _, _, _, _, _,
[ali], [okul],_, _, _)
|
|
S->Kisi Konu Fiil
|
aliyle toplantı var
|
takvimsem(_, _, _, _, _, _,
[ali], _,[toplanti], _, _)
|
|
S->Yer Konu Fiil
|
okulda toplantı var
|
Takvimsem(_, _, _, _, _, _,
_,[okulda],[toplanti], _, _)
|
|
S->Kisi Yer Konu Fiil
|
aliyle cananda toplantı var
|
takvimsem(_, 0, 8, 7, 5, 2003, [ali],
[canan], [toplanti], _, _)
|
|
S->Yer Kisi Konu Fiil
|
canandaki aliyle olan
toplantılari bul
|
takvimsem(_, _, _, _, _, _,
[ali], [canan], [olan,toplanti], _, _)
|
Timing Syntax Group:
|
Formula
|
Ornek
Cumle
|
�Semantik
|
|
S->Zamanalti Konu Fiil
|
onda toplantı var
|
takvimsem(_, 0, 10, 7, 5, 2003, _,
_, [toplanti], _, _)
|
|
S->Zamanalti Kisi Konu Fiil
|
on ellide aliyle toplantı
var
|
takvimsem(_, 50, 10, 7, 5, 2003, [ali], _, [toplanti], _,
_)
|
|
S->Zamanalti Yer Konu Fiil
|
on bucukta okulda toplantı
var
|
takvimsem(_, 30, 10, 7, 5, 2003, _, [okul], [toplanti], _,
_)
|
|
S->Zamanalti Kisi Yer Konu
Fiil
|
onbeş kırkbeşte
cananla taksimde toplantı var
|
takvimsem(_, 45, 15, 12, 5, 2003, [canan], [taksim],
[toplanti], _, _)
|
|
S->Zamanalti Yer Kisi Konu
Fiil
|
ona ceyrek kala okulda aliyle
toplantı var
|
takvimsem(_, 45, 9, 7, 5, 2003, [ali], [okul], [toplanti],
_, _)
|
|
S->Zamanustu Zamanalti Konu
Fiil
|
on mart ikibinellide on ellide
toplantı var
|
takvimsem(_, 50, 10, 10, 3, 2050, _, _, [toplanti], _, _)
|
|
S-> Zamanustu Konu Fiil
|
yarin toplantı var
|
takvimsem(_, 0, 8, 8, 5, 2003, _, _, [toplanti], _, _)
|
|
S-> Zamanustu Kisi Konu Fiil
|
haftaya aliyle toplantı
var
|
takvimsem(_, 0, 8, 14, 5, 2003, [ali], _, [toplanti], _, _)
|
|
S-> Kisi Zamanustu Konu Fiil
|
aliyle haftaya toplantı
var
|
takvimsem(_, 0, 8, 14, 5, 2003, [ali], _, [toplanti], _, _)
|
|
S-> Zamanustu Kisi Yer Konu
Fiil
|
iki gun sonra aliyle alilerde
toplantı var
|
takvimsem(_, 0, 8, 9, 5, 2003, [ali], [canan], [toplanti],
_, _)
|
|
S-> Zamanustu Yer Kisi Konu
Fiil
|
haftaya taksimde aliyle
toplantı var
|
takvimsem(_, 0, 8, 14, 5, 2003, [ali], [taksim],
[toplanti], _, _)
|
|
S-> Zamanustu Zamanalti Yer
Kisi Konu Fiil
|
onunda onda okulda aliyle
toplantı var
|
takvimsem(_, 0, 10, 10, 5, 2003, [ali], [okul], [toplanti],
_, _)
|
|
S-> Zamanustu Zamanalti Kisi
Yer Konu Fiil
|
yarin onikide canan ile
taksimde yemek var
|
takvimsem(_, 0, 12, 9, 5, 2003, [canan], [taksim], [yemek],
_, _)
|
|
S-> Zamanustu Zamanalti Kisi
Yer Konu Fiil
|
onikisinde saat onikide aliyle
taksimde toplantı var
|
takvimsem(_, 0, 12, 12, 5, 2003, [ali], [taksim],
[toplanti], _, _)
|
Duration Syntax Group:
|
Formula
|
Ornek
Cumle
|
�Semantik
|
|
S->Duration Konu Fiil
|
iki saatlik toplantı var
|
takvimsem(_, 0, 8, 9, 5, 2003, _,
_, [toplanti], dur(2, hour), _)
|
|
S->Zamanustu Duration Konu
Fiil
|
yarin on dakikalik yemek var var
|
takvimsem(_, 0, 8, 10, 5, 2003, _, _, [toplanti],
dur(10,minute), _)
|
|
S->Zamanustu Zamanalti
Duration Konu Fiil
|
yarin onda yarim saatlik toplantı var
|
takvimsem(_, 0, 10, 10, 5, 2003, _, _, [toplanti], dur(30,
minute), _)
|
|
S->Zamanustu Zamanalti
Kisi� Duration Konu Fiil
|
on ocak ikibinde on bucukta aliyle yarim saatlik
g�r�şme var
|
takvimsem(_, 30, 10, 10, 1, 2000, [ali], _, [gorusme], dur(30,
minute), _)
|
|
S->Zamanustu Zamanalti
Yer� Duration Konu Fiil
|
on gun sonra onbirde okulda yarim saatlik toplantı
var.
|
takvimsem(_, 0, 11, 22, 5, 2003, _, [okul], [toplanti], dur(30,
minute), _)
|
|
S->Zamanustu Zamanalti Kisi
Yer Duration Konu Fiil
|
on ocak ikibinde on bucukta aliyle okulda yarim saatlik
g�r�şme var
|
takvimsem(_, 30, 10, 10, 1,
2000, [ali], [okul], [gorusme], dur(30, minute
), _)
|
Recurring Syntax Group:
|
Formula
|
Ornek
Cumle
|
�Semantik
|
|
S-> Recurring Konu Fiil
|
haftada
bir toplantı var
|
takvimsem(_,
0, 8, 12, 5, 2003, _, _, [toplanti], _, recur(gun, 7, _, _, _, _, _, _))
|
|
S-> Recurring Yer Konu Fiil
|
her iki ayda bir ayin ikinci gununde okulda toplantı
var
|
takvimsem(_, 0, 8, 12, 5, 2003, _, [okul], [toplanti], _,
recur(month, 2, _, 2, _, _, _, _))
|
|
S-> Recurring Kisi Konu Fiil
|
haftada bir aliyle g�r�şme var
|
takvimsem(_, 0, 8, 12, 5, 2003, [ali], _, [gorusme], _,
recur(gun, 7, _, _, _, _, _, _))
|
|
S-> Zamanustu Recurring Konu
Fiil
|
on ocak ikibinden sonra haftada bir toplantı var
|
takvimsem(_, 0, 8, 10, 1, 2000, _, _, [toplanti], _,
recur(gun, 7, _, _, _, _, _, _))
|
|
S-> Zamanustu ile Zamanustu
arasında Recurring Konu Fiil
|
on ocak ikibin ile on mart
ikibin arasında haftada bir toplantı var
|
takvimsem(_, 0, 8, 10, 1, 2000, _, _, [toplanti], _,
recur(gun, 7, _, _, _, 10, 3, 2000))
|
|
S-> Zamanustu ile Zamanustu
arasında Recurring Yer Kisi Konu Fiil
|
on ocak ikibin ile on mart
ikibin arasında her temmuzun birinci pazartesisi okulda aliyle
toplantı var
|
takvimsem(_, 0, 8, 10, 1, 2000, [ali], [okul], [toplanti],
_, recur(year, 1, 7, 1, pazartesi, 10, 3, 2002))
|
|
S-> Zamanustu ile Zamanustu
arasında Recurring Konu Fiil
|
on ocak ikibin ile on mart
ikibin arasında haftada bir ikiser saatlik toplantı var
|
takvimsem(_, 0, 8, 10, 1, 2000, _, _, [toplanti], dur(2,
hour), recur(gun, 7, _, _, _, 10, 3, 2000))
|
Question Syntax Group:
|
Formula
|
Ornek Cumle
|
�Semantik
|
|
S-> Kisi Questionphrase Konu
Fiil
|
aliyle nerelerde toplantı
var
|
No semantic for questions.
|
|
S-> Yer Questionphrase Konu
Fiil
|
okulda kimlerle toplantı
var
|
|
S-> Zamanustu Questionphrae
Konu Fiil
|
haftaya kiminle toplantı
var
|
|
S-> Questionphrase Konu
|
kimlerle toplantı var
|