Türkçe Doğal Dil Arayüzülü bir Kişisel Takvim Programının, Tasarım ve Kodlaması
Şadi Evren ŞEKER, Dr. Birol Aygün; Prof. Dr. A. C. Cem Say ses@sadievrenseker.com,birolaygun@yahoo.com;say@boun.edu.tr
Bilgisayar Mühendisliği Bölümü
Yeditepe Üniversitesi, Istanbul, Turkey; Boğaziçi Üniversitesi, Istanbul, Turkey
project e-mail: tusa@shedai.net
Özet
Günümüzde hızla gelişmekte olan yapay zeka konularından birisi de doğal dil işlemedir. Bu konuda teorik pek çok çalışmanın yanı sıra, sınırlı sayıda pratik uygulama mevcuttur. Bu eksikliklerden birini doldurmak amacıyla yazılmış olan TuSA, doğal dil ara yüzüne sahip bir takvim programıdır. Amacımız, bilgisayar kullanma konusunda hiçbir bilgisi olmayan insanların, kolay bir şekilde randevularını kayıt edebilecekleri ve daha sonra sorgulayabilecekleri bir kişisel asistan geliştirmektir. Boğaziçi Üniversitesi’nde halen devam etmekte olan, TOY projesinde geliştirilen altyapıyı kullanan TuSA için yapılan sözdizimsel çalışmalarda, Türkçe’deki olası kişi, yer, konu, zaman ve soru cümle grupları analiz edilmiş ve listelenmiştir. Anlambilimsel alandaki çalışmalarda Türkçedeki bu kelime grupları için birer gösterim tasarlanmış, kayıtların tutulması için bir veritabanı oluşturulmuş ve girilen bilgilerin sorgulanabilir halde veritabanında tutulması sağlanmıştır.
Giriş
Projenin ismi ingilizce “Turkish Speaking Assistant” kelimelerinin birleşiminden oluşan TuSAdır. Projenin amacı, bilgisayar kullanma konusunda hiçbir bilgisi olmayan insanların, kolay bir şekilde randevularını kayıt edebilecekleri ve daha sonra sorgulayabilecekleri bir kişisel asistan geliştirmektir. Ancak ne yazık ki doğal dil arayüzü kullanılarak girilebilecek diyalogların tamamını içeren bir uygulama yazmak, günümüz koşulları için mümkün görülmemektedir. Bu yüzden küçük ve sınırları belirli bir küme içinde çalışmak tercih edilmiş ve toplantıları takib eden bir sekreter ile konuşulurken kullanılan cümleler projeye sınır olarak seçilmiştir. Bu sayede hem daha önce uygulaması bulunmayan bir konuda bir uygulama yazılmış olacak, hem de doğal dil işleme konusundaki bilgi birikimi hayata geçirilmiş olacaktır.
2. bölümde, bu konuda yapılmakta olan çalışmalar ve bu çalışmaların, TuSA ile ilişkisi incelenecektir. Seçtiğimiz hedefin küçük olmasına rağmen, TuSA, bizi limitler koymaya zorlayan, sonsuz sayıda olası cümle içeriyordu. 3. bölümde, karşılaşılan güçlükler ve bunlar için ürettiğimiz alternatif çözümleri incelenecektir. Proje devam ederken, günümüz teknolojisine adapte etmek için yapılan çalışmalar ise 4. bölümde incelenecektir. Projenin geliştirildiği ortam ve bu ortamın projeye yaptığı etkiler, 5. bölümde incelenecektir.
Doğal Dil ile İşleme
Günümüz yapay zeka konularından biri olan doğal dil ile işleme konusunun amacı, Türkçe gibi doğal bir dilde verilen cümleleri anlayabilmektir. Doğal dillerin, insanlar tarafından kullanılan, her geçen gün değişime uğrayan ve çoğu kez birden fazla anlam içeren cümleler içerdiği düşünüldüğünde, bu cümlelerin bilgisayarlar tarafından algılanmasının zorluğu ortaya çıkar. Doğal dil işleme konusu kendi içinde 4 ayrı bülümden oluşmaktadır. Bunlar Sesbilim, Sözdizim, Biçimbilim (ek ve kelime yapısı) ve Anlambilimdir. [1]
Sesbilim
Günlük hayatta insanların anlaşmak için kullandıkları doğal diller, yazılı olduğu kadar, sesli olarak da kullanılmaktadır. Biz TuSA projesinde sesbilim konuları ile uğraşmayıp, sadece yazılı girdileri ele aldık. Sesden metine çeviren bir modül ile, bu yapının eklenmesi ve TuSA nın sesli olarak kullanılabilmesi mümkündür.
Sözdizim
Kelimelerin cümle içerisinde bulundukları yerlere göre farklı anlamları vardır. Sözdizim, kelimelerin cümle içindeki anlamlarını takib eden bölümdür. Bir cümleyi meydana getiren yapılar, bazan bir kelime bazan da bir kelime grubu olabilir.
Biçimbilim
Cümledeki kelimelerin kök ve eklerinin ayrıştırılması, incelenmesi ve görevlerinin belirlenmesi biçimbirimsel çözümleme aşamasında yapılmaktadır.
Anlambilim
Ses, cümle ve kelimelerin analizinden sonra bu yapıların taşıdıkları anlamların anlaşılması ve bu anlama yönelik olarak eyleme geçilmesi bu aşamada yapılmaktadır.
TuSA
Bu bölümde, doğal dil işleme konularının TuSA'da nasıl uygulandığı anlatılacaktır. Hedefimiz, ajanda ile konuşulurken verilen bir cümlenin anlaşılıp, karşılığı olan komutun çalıştırılmasıdır. Girlen bütün cümle yapıları, iki ana başlık altında toplanabilir: 1. Veri giriş cümleleri. 2. Veri sorgulama cümleleri. Bütün veri giriş cümleleri, ileride sorgulanmak üzere veritabanında tutulmaktadır. TuSA, bu veri tabanında, ilgili alanları doldurmak için verilen cümleler üzerinde arama yapmaktadır. Örneğin aşağıdaki cümle TuSA tarafından algılanıp koşturulan bir veri giriş cümlesidir:
“On ocak ikibin ile, on mart ikibiniki arasında, her temmuz ayının ikinci pazartesisi, üniversiteden Ali ile, Yeditepe Üniversitesinde, ona çeyrek kala, ikişer saatlik, yemekli toplantı var.”
TuSA, bu cümleyi kelime kökleri, kelime ekleri ve sözdizim bilgilerine dayanarak, ileride anlambilim bölümünde anlatılacak olan, veri tabanı içindeki alanları doldurmak için kullanmaktadır.
Benzer şekilde aşağıdaki cümle de, TuSA tarafından algılanıp koşturulan bir veri sorgulama cümlesidir.
“Haftaya kaç adet toplantı var?”
Bu sorgulama cümlesi, veri giriş cümlesi ile aynı aşamalardan geçtikten sonra farklı bir komut koşturmaktadır.
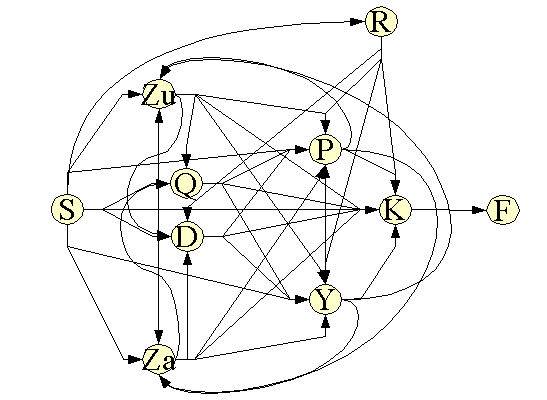
TuSA'ya verilen herhangi bir cümle Şekil 1'de gösterilen yollardan birini izler.
Şekil 1
TuSA ve Sözdizim
TuSA, doğal dil arayüzü kullanan bir ajanda programıdır. Bilgisayarlar üzerinde çalışan, gelişmiş ajanda programlarının çoğu (Örneğin MS Outlook [2]), toplantı bilgileri için kullanıcılardan bazı temel bilgiler istemektedir. Örneğin basit bir toplantı kayıdını tutabilmek için, toplantının yapılacağı yer, toplantıya katılacak kişiler, toplantının tekrar etme bilgisi, gibi opsiyonel bilgilerin dışında, toplantı tarihi, toplantı saati, toplantının konusu gibi temel ve zorunlu bilgileri kullanıcının girmesini ister. Bu bilgiler, ufak bir veritabanı üzerinde tutulup, kullanıcılara zaman çizelgesi şeklinde sunulmaktadır.
TuSA'nın yaklaşımı da benzer bir yol kullanarak, halihazırda mevcut bulunan, Kişi, Yer, Konu, Tarih, Saat, Uzunluk ve Tekrar bilgisi şeklinde hazırlanmış olan şablonu dolduracak kelime gruplarını yakalamaktır. Kullanılan Prolog dili kendi içinde bir veritabanı oluşturmaya imkan sağlamakta ve her kayıt veritabanında bu şablon kullanılarak tutulmaktadır. Bu kelime gruplarının özellikleri aşağıdaki şekildedir:
3.1.1. Kişi kelime grupları
Bu kelime grubunun özelliği toplantıda bulunacak kişilere ilişkin bilgiyi algılayıp, bunların isimlerini veritabanına yazacak olan anlambilim bölümüne göndermektir. Kişi kelime grupları, bir ya da daha çok özel isim içerebilmekte (Örneğin Ali, Veli, Canan ...) ya da “-le, -yla” gibi ekler almakta (Örneğin Aliyle, Cananla...) yada “ile” kelimesini içinde barındırmaktadır (Örneğin Ali Çavuş ile, Ali Bey ile, Ali Demir ile..). Biçimbirim bölümünün katkıları kullanılarak, kelimelerin kök ve ek yapıları incelenmekte, kök bilgisi kişi özel ismi içeren kelimeler, kişi kelime grubu olarak algılanmaktadır.
Bu yaklaşım yanında sorunlarla birlikte gelmektedir. Örneğin türkçede bulunan bütün ekleri girmek mümkün olsa bile, Türkçedeki bütün özel isimlerin girilmesi oldukça güçtür. Türkçedeki bütün isimler girilse bile, diğer kültürlerdeki bir özel ismi içeren kişi kelime grubunun algılanması mümkün olmamaktadır. Ayrıca kişi kelime grupları içlerinde özelisim olmayan kelimeler de barındırabilmektedir. (Ali Çavuş, Sayın Ali, Ali Bey, Canan Hanım gibi).
Bu sorunu çözmek için geliştirdiğimiz yöntem, Türkçenin bir özelliğinden faydalanmaktır. Türkçede, isim ve sıfat tamlamalarında tamlayanlar, tamlananlardan önce gelmektedir. Hangi kelime grubuna dahil olduğu anlaşılamayan kelimeler, hangi kelime grubundan önce geliyorsa o kelime grubunun bir üyesi olarak kabul edilmektedir.
Örneğin: “Okuldan tanıdığım uzun saçlı mavi gözlü Ali bey ile“ kelime grubu içinde TuSA tarafından tanınmayan pekçok kelime kökü içerse de kişi kelime grubu olarak kabul edilmektedir. Bunu sağlayan özellik kelime grubunun sonunda bulunan “ile” bağlacıdır. Bu yaklaşımın da yan etkileri vardır. Bu yan etkiler ve çözümleri, ilerleyen bölümlerde incelenecektir.
Yer kelime grupları
TuSA tarafından algılanmaya çalışılan diğer bir kelime grubu da toplantının yapılacağı yeri içeren yer kelime grubudur. Kişi kelime grubuna benzer şekilde, yer kelime grubuna dahil olan kelimeleri algılamak için de bu kelime grubuna özgü özellikler kullanılmaktadır. Yer kelime grupları ya kelimenin tabiatı itibariyle yer olan kökler içermekte (okul, restoran gibi) ya da -de -da ekleriyle yer belirten ismin -de halini almaktadır. (bizde, evde gibi). Örneğin Osmanbey kelime grubu hem kişi hem de yer kelime grubu olarak algılanmaya uygundur. Nasıl bir kelime grubu oldugunu biçimbirim bölümünün incelemesi sonucunda aldığı ek bize söylemektedir. TuSA, “Osmanbeyde” kelimesini yer, “Osmanbeyle” kelimesini kişi olarak algılanmaktadır. Benzer şekilde bir kelimenin kökü kişi özel ismi olduğu halde yer bilgisi olarak kullanılabilmektedir. Örneğin “Aliyle Cananda toplantı var”, cümlesinde kişi özel ismi olan “Ali” ile “Canan”ın görevleri farklıdır ve bu farkı bize biçimbirim anlatmaktadır.
Kişi kelime gruplarına benzer şekilde, yer kelime grupları da tek başına incelendiğinde yer olmayan, ancak başka bir yer kelime grubu ile kullanıldığında, bu yer kelime grubu içinde algılanabilecek kelimeler içerebilmektedir. Örneğin “bahçeli okul”, “bizim üniversite”, “komşumuz cananda” gibi. Bu kelime gruplarının özelliği, tamlayanlarının başta oluşu ve hepsinin mutlaka bir yer kelime grubu ile bitmesidir. Aksi takdirde, bütün yer olabilecek kelime köklerinin girilmesi mümkün olmamaktadır. Bu kelimelerin hangi gruba dahil olduğunun anlaşılmasının güçlüğü yanında, hiç bilinmeyen kelimelerin de zaman içinde kullanılması mümkündür. Örneğin “Ali ile kırmızı bölgede toplantı var”, şeklinde duruma özgü yer isimleri kullanılabilmekte ve bunlar daha önceden bilinmeyen kelimeler olabilmektedir.
Kişi kelime gruplarında bahsedilmeyen ancak hem yer, hem kişi, hem de ileride anlatılacak olan konu kelime grupları, ortak bir sorun taşımaktadırlar. Şayet bazı kelimeleri hiç analiz etmeden, sadece bildiğimiz bir yer, kişi yada konu kelime grubunun önünde diye bu kelime grubuna dahil ediyorsak, bizim için onemli ve anlamlı bir kelime grubunu burada kaybetmemiz mümkdür. Örneğin, “Ali bey ile canan hanımda toplantı var” şeklindeki bir cümlede, “hanımda” kelimesi yer kelime grubudur. Sonunda bulunduğu kelimeleri de yer kelime grubunun bir üyesi yapar. Bu durumda aslında kişi kelime gurubu olan “Ali bey ile” kelimeleri toplantının yapılacağı yer kısmına yazılmak tehlikesiyle karşı karşıyadır.
Bu sorunu çözmek için, Prologun sunduğu, kurallar önceliği özelliği kullanıldı. Prolog, bir eylem için birden fazla çözüm içerebilen ve bu çözümler arasında öncelik uygulayabilen bir yapıya sahiptir. Bu özellik kullanılarak, uzman sistemlerde kullanılan kuraltabanına benzer bir taban oluşturulup, önceliği olan kuralların önce çalışması sağlanmıştır. Yani yer kelime grubundan önce, daha öncelikli olan yer olmayanlar kelime grubu çalıştırılmaktadır. Bu sayede kişi, konu, zaman gibi diğer kelime gruplarının yer olarak algılanması engellenmektedir. Örneğin, “Ali bey ile canan hanımda toplantı var” cümlesi TuSA tarafından analiz edilirken, kelime kelime incelenir. Yer kelime grubunu daha önce yakalıyorsak, yer olmayanlar kelime gurubu içindeki kişi kelime grubu tarafından yakalanıp, yer kelime grubundan atılır. Bu durumda hangi kelime grubunda olduğu belirli olmayan kelimeler tekrar analiz edilip, uygun kelime grubu bulununcaya kadar (bu durumda kişi kelime grubu) bu analiz böylece devam etmektedir.
Konu kelime grupları
Bu kelime grubu bütün ajanda programlarının temelini oluşturan toplantının konusunu algılamaya yaramaktadır. Yaptığımız kabuller dahilinde, bir toplantının konusunun olmaması mümkün değildir. Bir toplantının hiç konusu olmaması durumda bile toplantı olması itibariyle bir konusu vardır. Yani Türkçe'de bir toplantıyı konusu olmasa bile ifade ederken toplantı kelimesi kullanılır. “Ali ile okulda toplantı var” cümlesinde, toplantıda ne yapılacağı ile ilgili bilgi bulunmamaktadır, ancak toplantı kelimesi, türkçenin tabiatı itibariyle kullanılmıştır. İşte bu sebepten dolayı TuSA bütün girdilerinde konu kelime grubunu arar.
Konu kelime grupları, bundan önce anlatılmış olan kişi ve yer kelime gruplarıyla yakın benzerlik gösterirler. Ancak konu kelime gruplarının ayırt edici ek yada kökleri bulunmamaktadır. Türkçede kullanılabilen hemen her kelime, konu kelime grubu olarak kullanılabilir. Bu sorun bizi bir kabul yapmaya zorlamıştır. TuSA bütün konu kelime gruplarını eylemden hemen önce aramakta ve kelime grubunun bittiğini ancak tanıdığı bir eylem gördükten sonra anlayabilmektedir. Örneğin “Öğretim görevlileriyle toplantı salonunda ali beyin yüksek lisans tezini değerlendirme toplantısı var” şeklindeki bir cümlede, daha önceden anlatıldığı gibi “Öğretim gorevlileriyle” kişi kelime grubu, “toplantı salonunda” yer kelime grubu olarak algılanırken, “ali beyin yüksek lisans tezini değerlendirme toplantısı” kelimeleri konu kelime grubu olarak algılanmıştır. Bunun sebebi her ne kadar içinde “ali bey” gibi kişi kelime grubuna girmeye uygun kelimeler barındırsa da, “var” eyleminden hemen önce gelmesi ve toplantının kişi kelime grubunun daha önceden zaten bulunmuş olmasıdır.
Zaman Kelime grupları
Bir ajanda programının en temel özelliklerinden olan zaman bilgisi, bu kelime grubu yardımıyla algılanmaktadır. Ancak TuSA kullanıcısına bu kelime grubunun girilmesi yönünde bir zorlama yapmamakta, bu kelime grubunun girilmemesi durumunda girdinin yapıldığı tarihi toplantı tarihi olarak kabul etmektedir. Örneğin “Pazarlama departmanında pazarlama ekibiyle pazarlama konularında bir toplantı var” şeklinde bir cümle girildiği zaman bu kelime grupları arasında zaman bilgisi bulunmadığı için, TuSA kayıdın girildiği tarihi toplantı tarihi olarak kabul eder.
Zaman kelime gruplarına özgü bir sorunda, aslında doğal dillerin iki ayrı zaman kelime grubu içermesidir. Örneğin “saat altıda” gün içinde zaman bildirmekteyken, “ayın onunda” tarih belirtmektedir. Bu sorundan dolayı TuSA iki ayrı zaman kelime grubu içermektedir.
Zamanaltı (saat): Gün içindeki zaman kelimelerini tutar. Örneğin “onda”.
Zamanüstü (tarih): Tarih bilgilerini tutar. Örneğin “onunda”.
Türkçede bir toplantı bilgisi iki ayrı şekilde verilebilir:
Kesin tarih veya saat. Örneğin “onda” veya “onunda”.
Dolaylı tarih veya saat. Örneğin “on saat kırk dakika sonra” veya “on gün iki ay üç yıl sonra” gibi.
Bir bilgisayar programı için, en büyük sorunlardan birisi de, doğal dillerde zaman kelime grupları için son derece zengin kullanımlar olmasıdır. Örneğin aşağıdaki kelime grupları TuSA tarafından kabul edilen kelime gruplarından sadece bazılarıdır.
“onunda”, ”on ocakta”, “ikinci ayın onunda”, “on mart ikibinde”, “martın onunda”, “ikibinin üçüncü ayının onuncu günü”, “on ellide”, “ona çeyrek kala”, “yarımda” ...
Bu zengin kullanım, bazı kabuller yapılmasını da beraberinde getirir. Örneğin “saat onda” denildiği zaman, sabah on veya akşam on anlaşılabilmektedir. Bu durum aynı gün içerisindeki toplantılar için, önümüzdeki ilk on şeklinde çözülebilse de, ileri tarihlerdeki toplantıların saati verilmesi durumunda belirsizliğe sebep olmaktadır. Bu soruna çözüm olarak TuSA tarafından 24 saatlik gösterim kullanılmaktadır. Ancak bu kabullere rağmen TuSA oldukça fazla sayıda hesap yapmaktadır. Örneğin “martın ilk pazartesisi” denildiği zaman geçmişe bir toplantı eklenmesi daha anlamsız olduğu için, önümüzdeki ilk mart ayının ilk pazartesi günü bulunmakta ve bu tarih, ilerideki sorgulamalar için, sayısal olarak Gün, Ay, Yıl şeklinde veritabanına yazılmaktadır.Diğer bir sorun, zamanüstü ve zamanaltı kelime gruplarının birbirine kelime kökleri açısından yakın oluşudur. Bu sorun biçimbirim bölümünde daha detaylı anlatılacaktır.
Uzunluk Kelime grupları
Toplantıların uzunluğu, bir toplantının ne kadar süreceği bilgisi bu kelime grubu tarafından algılanmaktadır. Örneğin “onunda onda iki saatlik bir toplantı var” şeklindeki bir cümlede “iki saatlik” kelimeleri, toplantının uzunluğunu vermektedir. Bu kelime grubunun sözdizimsel olarak daha önceden anlatılmamış kendine has bir özelliği bulunmamaktadır. Bu kelime grubu ile ilgili daha detaylı bilgi biçimbirim bölümünde incelencektir.
Tekrar kelime grupları(Recurring Events)
Bir toplantının belirli periyotlarda tekrar etmesi durumunda, bu toplantı tekrarlı toplantı olarak kabul edilir. Örneğin “önümüzdeki salıdan başlayarak iki haftada bir mustafa beyle toplantı var” şeklindeki bir cümle tek bir toplantı yerine sonu olmayan sayıdaki toplantıyı ifade etmektedir. Çıkış noktası itibariyle zamanüstü kelime gruplarına benzeyen tekrar kelime grupları hem kullanım hemde veritabanında saklanması şekliyle farklılık gösterirler. Tekrarlı cümlelerin veritabanında nasıl tutulduğu, anlambilim bölümünde daha detaylı anlatılacaktır. Ancak sözdizimsel olarak incelendiğinde 3 tip tekrar kelime grubu bulunmaktadır. Bunlar günlük, haftalık veya aylık tekrar kelime grupları olabilir. Örneğin “iki günde bir” kelime grubunun periyodu günlük birimdedir. Benzer şekilde “iki haftada bir” kelime grubunun periyodu her ne kadar hafta kelimesi kullanılsa da günlük boyutta incelenebilir. Haftanın 7 gün olması yüzünden aslında “iki haftada bir” kelime grubu “14 günde bir toplantı var” şeklinde çevrilebilir. Ancak “ayın üçünde” kelime grubu, aylık kelime grubu olarak incelenmelidir. Çünkü, ayın 30 gün olarak kabul edilip günlük boyuta indirilmesi mümkün değildir. Benzer şekilde “her iki temmuzda” şeklindeki bir kelime grubu ne aylık ne de günlük olarak ifade edilemez.
Tekrarlı kelime grupları ile ilgili diğer bir sorun da, tekrarların başlangıç ve bitiş tarihleridir. İleride anlambilimsel alanda da anlatılacağı gibi başlangıç tarihi verilmeyen tekrarlı toplantıların başlangıç tarihi toplantının girildiği gün olarak kabul edilmiştir. Dolayısıyla bütün tekrarlı toplantıların aslında birer başlangıç tarihi bulunmaktadır. Ancak bitiş durumuna göre:
Sonlu tekrarlılar
Sonsuz tekrarlılar
şeklinde incelemek gerekir. O halde sonlu tekrarlı toplantıların bir de bitiş tarihinin girilmesi söz konusudur. Bu duruma başlangıç tarihi de eklenirse 3 ayrı kelime grubunun tekrarlı kelime grupları tarafından algılanması gerekir. Örneğin “on ocak ikibin ile on mart ikibiniki arasında her temmuzun birinci pazartesisi” şeklinde verilen bir kelime grubu TuSA tarafından doğru bir şekilde algılanmaktadır. Bunu yaparken TuSA, daha önceden tanımlanmış olan zamanüstü kelime gruplarından yararlanmaktadır. Tekrarlı toplantının başlangıç tarihi, toplantı tekrarlı olmasaydı, toplantının tarihi olacaktı. O halde zamanüstü alanı aslında tekrarın başlangıç bilgisini barındırmaktadır.
Soru kelime grupları
TuSA, hem veri girişi hem de veri sorgulamasına imkan veren bir doğal dil arayüzüne sahiptir. Sorgulama cümleleri iki şekilde olabilir:
Normal cümlelerin sorgulama fiili içeren halleri. Örneğin “aliyle toplantıları göster”.
Soru kelimesi içeren cümleler. Örneğin “Aliyle ne zaman toplantı var”.
Sorgulama fiili içeren hallerde, cümle normal bir cümle gibi incelenmekte, yapılacak işlemi anlambilim aşaması çözmektedir.
Soru kelimesi içeren cümlelerde de bazı bilgiler verilip eksik olan bilgilerin sorgulanması şeklinde bir yöntem izlenmektedir. TuSA'nın şu anda kabul ettiği soru kelimeleri: ”Ne, Kim, Ne zaman, Nerede”dir.
TuSA ve Biçimbirim
Bu bölümde, kelime kökleri ve ekleri konularında TuSA'nın çalışması incelenmektedir. Sözdizim bölümünde anlatılmış olan kelime gruplarının ayırt edilmesinde önemli bir yer tutan bu bölüm, halihazırda var olan bir biçimbirimsel analiz programını kullanmaktadır. Boğaziçi Üniversitesi Bilgisayar Mühendisliği Bölümünde halen devam etmekte olan TOY[3] projesinde geliştirilen biçimbirimsel yapıyı kullanan TuSA, bu alt yapıyı kullanan ilk uygulama olduğu için, bu alandaki bazı eksikliklerin daha iyi görülmesi ve eklemeler yapılmasını da sağlamıştır. Örneğin sayma sayıları yada “Şimdiki” gibi zaman köklerine eklenen -ki eki, bu programda bulunmayan ve TuSA projesi sayesinde eklenen örneklerdir.
TuSA ve Anlambilim
Sözdizim bölümünden çıkan şemalar, anlambilim bölümüne gösterilir. Örneğin, “on ocak ikibin ile on mart ikibiniki arasinda her temmuzun birinci pazartesisi yeditepe üniversitesi bilgisayar mühendisliği bölümünde profesör nadir bey ile ikişer saatlik toplantı var” şeklindeki bir cümle daha önceden anlatıldığı gibi, sözdizimsel öğelerine bölünüp, her öğe için bir şema çıkartılır. TuSA'nın aradığı 11 bölüm vardır. Bunlardan ilki kayıtları ayırt etmek için otomatik olarak arttırılan bir tanımlama sayısıdır. Bu sayıyı, dakika, saat, gün, ay, yıl, yer, kişi, konu, uzunluk ve tekrar bilgileri izler. Bu durumda “on ocak ikibin” zamanüstü öğesi olarak algılanıp, “zu-10-1-2000” şeklinde bir şema oluşturmaktadır. Benzer şekilde “iki gün sonra” denildiği zaman “aft-gun-2” şeklinde anlamsız görünen bir şema oluşturulmaktadır. Ancak bu şemalar, TuSA'nın anlambilim bölümünde anlamlı hale gelmektedir. TuSA'nın genel şeması, “takvim(ID, Dakika, Saat, Gün, Ay, Yıl, Kişi, Yer, Konu, Uzunluk, Tekrar).” şeklindeki bir Prolog önermesidir. TuSA'nın anlambilim bölümü anlamsız olan “aft-gun-2” şemasını alıp, kaydın girildiği tarihe 2 gün eklenilmesini bulup bu işlemi yaptıktan sonra TuSA'nın genel şemasına yerleştiren bölümdür. Benzer şekilde diğer kelime gruplarının da yerleştirilmesinden sonra yukarıda verilmiş olan uzun cümlenin TuSA'nın iç gösterimindeki karşılığı: “takvim(248, 0, 8, 10, 1, 2000, [profesör, nadir, bey], [yeditepe, üniversitesi, bilgisayar, mühendisliği ], [toplanti], 120, recur(year, 1, 7, 1, pazartesi, 10, 3, 2002)).” şeklindedir.
Bu bilgi TuSA'nın içinde tutulmakta ve ilerideki sorgulamalar için bir dosyaya yazılmaktadır. Cümlenin sonunda bulunan “var” kelimesi TuSA'ya bu toplantının kayıt edilmesi gereken bir toplantı olduğunu ve kaydedip dosyaya yazmasını söylemektedir. Şayet “aliyle toplantıları göster” şeklinde bir cümle girilmiş olsaydı. Cümle sonundaki göster fiili, bir önceki “var” fiilinden farklı olarak, sorgulama anlamı taşıyacak ve anlambilim bölümü bu bilgileri dosyaya kaydetmek yerine dosya içinde bu bilgilere uygun kayıtları bulup görüntüleyecekti.
Yan Çalışmalar
TuSA'nın yazımı sırasında kullanılan ortama ilave olarak, bütün dünyaya açık bir şekilde çalışabilmesi hedeflenmiştir. Bu hedef uğruna TuSA'nın İnternet üzerinden çalışabilmesi için Prolog dili kullanılarak CGI arayüzü ile internete deneme sürümü konulmuştur. Ancak internet sürümünde TuSA'nın bazı eksiklikleri vardır. Örneğin, kayıt aranılırken, şayet birden fazla kayıt uygun bulunursa, bu durumda sadece birisi görüntülenebilmektedir. Bunun sebebi CGI üzerinden o anda tek kayıdın geçebilmesidir. Ancak bu çalışma ileride daha gelişmiş projelerin geliştirilebilmesi için bir ufuk açmıştır. Örneğin ileride kişi takibi yapıp, birden fazla kişinin toplantı bilgilerinin tutulmasını sağlayabilir. Benzer şekilde TuSA için XPCE kullanılarak grafiksel arayüz kullanan bir modül yazılması söz konusudur. Proje için yapılması planlanan çalışmalardan birisi de, sesli diyalogların algılanabilmesi için sesbilim eklentisi yapılmasıdır. Ancak ne yazıkki henüz bu konuda çalışmalar başlamamıştır.
Geliştirme Ortamı
TuSA'nın geliştirme ortamı, Linux üzerinde Prolog programlama dilidir. Prolog dilinin yorumlanan bir dil olması sayesinde, yorumlayıcısının çalıştığı bütün ortamlarda çalışabilmektedir. Örneğin Windows ortamında test edilmiş ve çalışmasında hiçbir sorun yaşanmamıştır. Ancak Linux üzerinde geliştirilirken türkçe karakter kullanması gereken TuSA'nın bazı sorunlar yaşaması sözkonusu olmuştur. Bu sorunlar standartlaştırılmış bir karakter takımı kullanılarak çözülmüştür.
Sonuç
Bu proje, Türkçe için yapılmış ilk doğal dil arayüzlü ajanda programıdır. Doğal dil arayüzü olan bir program yazmanın ne kadar mümkün olduğunu, ve bu tip bir proje yazarken izlenilmesi gereken yolların daha iyi görülmesini sağlamıştır. Kullanılan yöntem ne tam olarak anahtar kelime aramaya, ne örüntü işlemeye(pattern matching) ne de sözdizimsel analize girmektedir. İhtiyaçlar doğrultusunda, bu makalede anlatıldığı gibi hepsinden bağımsız özgün bir yöntem kullanılmıştır. Sonuçta çalışan bir program çıkmış ve mümkün olduğunca doğal dilden uzaklaşmayan bir arayüz bu programa başarıyla eklenmiştir.
Referanslar
[1] Covington M. A. Natural Language Processing for Prolog Programmers, Prentice Hall, New Jersey, 1994
[2] Microsoft Office, http://www.microsoft.com/office/outlook/default.asp
[3] Çetinoğlu Ö. A Prolog Based Natural Language Processing Infrastructure for Turkish, M.S. Thesis, Boğaziçi Üniversitesi, 2001