PhD. Thesis Preliminary Report
Written by: Sadi Evren SEKER
Advisor: Assoc. Prof. Banu DIRI
Topic: Turkish Semantic Search Engine
Statement of Purpose: Our aim is implementing a software to track internet pages and index turkish pages for intelligent search.
Introduction: Besides the difficulties of reaching an information, Internet is the largest data source of the world. Unfortunetly most of the languages are lack of smart implementations to utilize this information. Almost 90% of the information in internet is in natural language and using computers to extract such an information is only available after the natural language processing studies. Heading a language study in an environment like Internet makes it necessary to declare a formal way of categorisation of Internet pages.
Analysis: Since there are more than 40 search engines available in turkish, most of them are lack of natural language operations. Unfortunetly almost all of them are static search engines which can search only in a static database which is filled with an operator or the site owners.
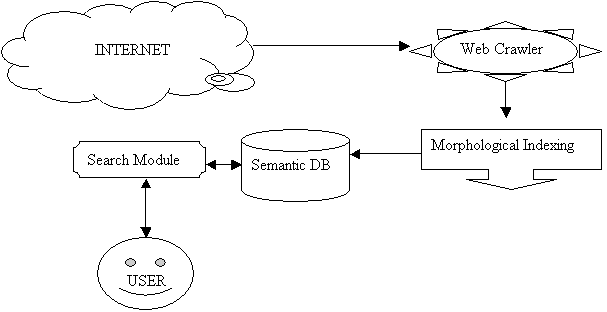
Possible steps:
- Web Crawler
- Network module to connect internet
- Web site fetcher
- Html parser
- Multi threaded or multi process link tracker
- An efficient time to live for each page (to turn back and refresh information about the pages)
- Indexing
- Link tracker
- String operations to fetch words
- NLP operations to understand the language of page
- Morphological analysis to get semantic representation of the words
- Stop words
- Database
- Keeping information of link and semantic representations
- An efficient compression method
- Search module
- An interface for users to search web sites
- Morphological analysis to get semantic representation of search words
- Compression and database seach for the results
Possible environment:
For the network modules JAVA is a good alternative because of unrivalled network classes. On the other hand because of predicate calculus abilities and built-in rdbs prolog is the strongest nlp programming environment for this project. JPL may be the intersection set of java and prolog while interchanging the information between network and nlp modules. On the other hand the database implementation requires great amount of memory and a reliable server to keep whole database in memory.
Since turkish is an agglutinative language, we can build any word by using roots and suffixes. While building any word we can use a finite state machine. Indexing all the words in a web page requires huge amount of storage and time consuming. To solve the problem we can apply hughes algorithm for data compression. The most suitable part of compression is the conversion of letter groups to symbols is already done while traversing the finite statemachine. If we append the track of every nodes in the machine to the root of the word, we can find out a unique morphological representation. [burada ambiguity olabilir]
Language related studies:
- stop words
- time to live for a web page (the update frequencies of the web pages)
- how to determine the language of a web page (to look the charachter set of the web page) (fetch random words from the webpage and try to pass from morphological analyzer) (what if a user types without using turkish charachters, what if a page contains quotations)
Crawler related studies:
- tracking links
- finding duplicate web links
- finding circular links.
-