şekil tanıma dersi final projesi ilerleme raporu
Yazan : Şadi Evren ŞEKER
Dersin Hocası: Elif Karslıgil
DDKT (doğal dil ile karakter tanıma)
Amaç
Bu projenin amacı, optik olarak taranmış bir yazının içerisinde geçen metni tanımaktır. Bu çalışma kapsamında yazının içerisinden karakter bazlı olarak şekil tanıma yapılmış daha sonra kelimeler inşa edilmiştir. Cümle seviyesi bu çalışmanın kapsamı dışındadır. Yine bu çalışma kapsamında resim işlerken normalizasyon ve parazit azaltma gibi yöntemler kullanılmamıştır.
Giriş
Günümüzde artan bilgi teknolojisi ve inanılmaz bir hızla artan İnternet göz önüne alındığında, insanlık hiç olmadığı kadar, doğru şekilde işlenemeyen ve işlemek için ancak insan faktörünün gerektiği çok büyük miktarda veri ile karşı karşıyadır. Bu problemin çözülmesi için insanı taklit eden yapay yazılımlar üzerinde yapılan çalışmalar hızla artmaktadır.
Genellikle veri işleyen sistemlerin bir amacı olur ve bir karar vermeleri beklenir. Örneğin devam etmekte olan doktora çalışmamda bir İnternet arama motorunun aranan cümlelerin anlamı konusunda bir karar vermesi ve bu sonuca uygun bulduğu sayfaları göstermesi veya cevap vermesi beklenmektedir. Karar verme mekanizmasının sağlıklı çalışması ve istenilen sonuca ulaşması için günümüz teknolojilerinde henüz tam başarı elde edilememiştir.
Başarının tanımı ve ölçüsü konusunda tartışmalar olmasına karşılık ortalama bir insan seviyesinde başarı bu çalışma kapsamında başarı olarak kabul edilecektir.
Dolayısıyla bu çalışma kapsamında herhangi bir karar verme mekanizması geliştirmekten çok, bir karar verme mekanizmasının ileride kullanacağı bir alt yapı hazırlamak amaçlanmıştır.
Bu dökümanın yapısı yazılım mühendisliği tekniklerinden doğrusal yöntem (linear method, waterfall method) göz önüne alınarak hazırlanmıştır. Buna göre projenin geliştrilmesinde ve dökümantasyonunda, analiz, tasarım, kodlama ve test aşamaları sırasıyla ele alınmıştır.
Analiz ve Tasarım
Proje kapsamında istenilen bir resmin içerdiği bilginin Türkçe cümleler olarak algılanmasıdır.
Daha önceden yapılan çalışmalar proje öneri raporunda belirtilmiş olup ne yazık ki doğal dilden faydalanarak yapılan bir çalışmaya rastlanılmamıştır. Daha önceden yapılmış olan çalışmamız kapsamında doğal dilde kelime işlemenin başarısının muadili olan n-gram yöntemlerine göre başarılı olduğu ortaya konulmuştu. Bu özellikten faydalanarak şekil tanıma konusunda ilk kez Türkçe için doğal dil özellikleri kullanarak mevcut model üzerinde iyileştirmeye gidilmesi amaçlanmıştır.
Bu amaçla şekil tanıma çalışmaları üzerinde yapılan araştırmalar sonucunda şekillerin tanınmasını kolaylaştırmak amacıyla şekil üzerinde gürültü ve deformasyon olmadığı varsayılmıştır, çünkü yapılmakta olan iyileştirme resim işleme ve özellik çıkarımı gibi konuları değil anlambilimsel(semantic) bir çalışmayı kapsamaktadır.
Buna göre elde edilen karakter tanıma işlemi doğal dil işlemeden geçirilerek başarısı arttırılmıştır, karakter tanıma seviyesinde yapılabilecek iyileştirmeler de elbette çalışmanın başarısını arttıracaktır.
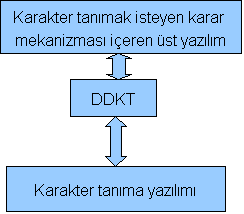
Yukarıdaki şekilde DDKT projesinin yerleşmiş olduğu katman gösterilmiştir. Buna göre hedeflenen amaç karakter tanıma yazılımlarının üzerine oturarak karakter tanıma hatalarını asgariye indirmektir.
Ancak yapılan çalışma bir şekil tanıma deri çalışması olduğu için, DDKT katmanı karakter tanıma yazılımının içerisine gömülmüş ve karakter daha tanınırken sonucu etkilemesi amaçlanmıştır.
Buna göre katmanlı uygulamada, tanınan karakterlerin birleştirilerek üst katmana verilmesi ve üst katmanda iyileştirilmesi amaçlanırken, bu çalışmada, her kelimenin tanınması sırasında daha önceden tanınmış olan karakterlerin sonucu etkilemesi amaçlanmıştır.
Bu durum bir örnek üzerinde anlatılacak olursa:
Örneğin ilk karakter ş harfi olarak tanınmış olsun. İkinci harf doğal dil bilgisine göre asla b, c, d gibi sessiz harf olamaz. Olabilecek harfler aşağıdaki ağaçta gösterildiği gibidir (aşağıdaki ağaç daha önce yapılan bir çalışmada kullanılan trie ağacıdır):
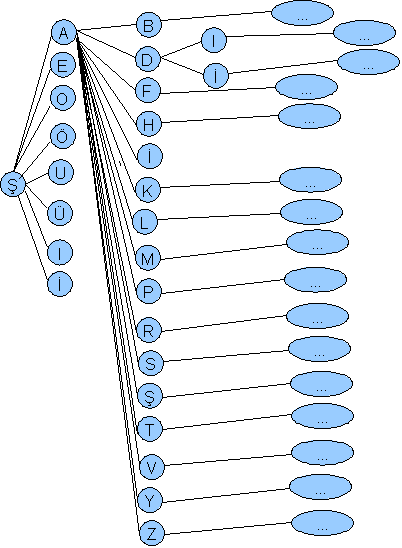
Yukarıdaki şekilde Türkçe için başlangıç harfi Ş olan kelimelerin alabileceği devam yolları ŞADİ kelimesi için incelenmiştir. Buna göre örneğin Türkçede ŞAD harflerinden sonra I veya İ harfi gelebilmekte bunun dışındaki bir harfle devam eden bir Türkçe kelime bulunmamaktadır.
Dolayısıyla bu projedeki amaç, herhangi bir harf tespit edildikten sonra bir sonraki harfin önceden tespit edilen harften etkilenmesidir.
Hemen akla gelebilecek önemli bir nokta kelimenin ilk harfinin yanlış tespit edilmesi durumudur. Bunun için grafikte hiçbir zaman olasılık %100 olarak verilmemekte her zaman geri dönülerek (back track) diğer alternatiflerin incelenmesi açık bırakılmaktadır.
Yukarıda anlatılan bu özelliklerin başarılı bir şekilde sisteme uyarlanması için en uygun model olarak multi layer perceptron yönteminin kullanılmasına karar verilmiştir. Buna göre harflerin tespitinde kullanılan perceptronlardan birisi doğal dil etkisi olarak tasarlanmıştır.
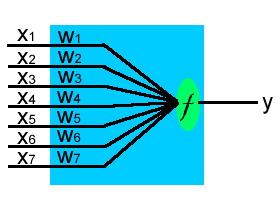
Yukarıdaki grafikte örnek bir tek seviyeli perceptron gösterilmektedir. Buna göre 7 farklı girdiin her birisi kendisine atanan ağarlıklarla çarpılarak bir f fonksiyonundan geçtikten sonra sonuç elde edilmektedir.
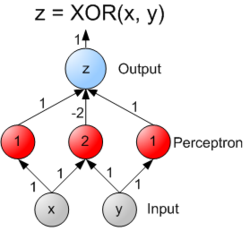
Çok seviyeli (multi layer perceptron) ise yukarıda gösterilmiştir buna göre her seviyeden sonra çıkan sonuçlar yeni birer girdi olarak bir sonraki seviyeye girmektedir. Örneğin yukarıdaki grafikte XOR işleminin çok katmanlı perceptron uyarlaması gösterilmektedir.
Buna göre projemizde hedeflenen doğal dil işleme etkisinin bir Ya da daha fazla seviyede sonucu etkilemesidir.
Multi layer pereptron uygulamasının eğitim işlemi çok uzun sürdüğü için eğitim sonuçlarının bir dosyada saklanarak daha sonraki aşamalarda eğitimiş verinin kullanılması da hedeflenmektedir.